搜索到
44
篇与
码海
的结果
-
 Typecho(1.2.1)免密登录研究笔记 最近在研究 Spring Cloud 微服务 框架,便研究了一下它的OAuth2认证模式,想着在Typecho中也对接下,后面就不用再次输入账号密码了,很是方便。其中技术难点,是 Typecho 的免密登录方式,看到官方文档说的是封装在了Widget_User组件中,开发人员可调用此组件免密登录。但是验证了好久,都无法登录成功,又研究了聚合登录的插件中的免密登录(见下方)方法,也不是很好使。//使用用户uid登录 private function useUidLogin($uid, $expire = 0) { $authCode = function_exists('openssl_random_pseudo_bytes') ? bin2hex(openssl_random_pseudo_bytes(16)) : sha1(Typecho_Common::randString(20)); $user = array('uid'=>$uid,'authCode'=>$authCode); Typecho_Cookie::set('__typecho_uid', $uid, $expire); Typecho_Cookie::set('__typecho_authCode', Typecho_Common::hash($authCode), $expire); //更新最后登录时间以及验证码 $this->db->query($this->db ->update('table.users') ->expression('logged', 'activated') ->rows(array('authCode' => $authCode)) ->where('uid = ?', $uid)); }这个是根据用户的 uid 进行免密登录,但是调用 $this->user->hasLogin() 来判断用户是否登录,一直是 false;查了查资料,看到了一篇《Typecho不改核心代码实现自定义登录、注册功能》文档,然后给了一个思路,研究一下1.2.1版本用户那块的代码;在/var/Widget/User.php中,用户登录跟聚合登录的方式一样,但是就是不好使,再向下有一个方法,叫 simpleLogin; 注解也写的很好“只需要提供uid或者完整user数组即可登录的方法, 多用于插件等特殊场合”,直接调用 $this->user->simpleLogin($uid),即可登录成功。只要思想不滑坡,方法总比困难多。
Typecho(1.2.1)免密登录研究笔记 最近在研究 Spring Cloud 微服务 框架,便研究了一下它的OAuth2认证模式,想着在Typecho中也对接下,后面就不用再次输入账号密码了,很是方便。其中技术难点,是 Typecho 的免密登录方式,看到官方文档说的是封装在了Widget_User组件中,开发人员可调用此组件免密登录。但是验证了好久,都无法登录成功,又研究了聚合登录的插件中的免密登录(见下方)方法,也不是很好使。//使用用户uid登录 private function useUidLogin($uid, $expire = 0) { $authCode = function_exists('openssl_random_pseudo_bytes') ? bin2hex(openssl_random_pseudo_bytes(16)) : sha1(Typecho_Common::randString(20)); $user = array('uid'=>$uid,'authCode'=>$authCode); Typecho_Cookie::set('__typecho_uid', $uid, $expire); Typecho_Cookie::set('__typecho_authCode', Typecho_Common::hash($authCode), $expire); //更新最后登录时间以及验证码 $this->db->query($this->db ->update('table.users') ->expression('logged', 'activated') ->rows(array('authCode' => $authCode)) ->where('uid = ?', $uid)); }这个是根据用户的 uid 进行免密登录,但是调用 $this->user->hasLogin() 来判断用户是否登录,一直是 false;查了查资料,看到了一篇《Typecho不改核心代码实现自定义登录、注册功能》文档,然后给了一个思路,研究一下1.2.1版本用户那块的代码;在/var/Widget/User.php中,用户登录跟聚合登录的方式一样,但是就是不好使,再向下有一个方法,叫 simpleLogin; 注解也写的很好“只需要提供uid或者完整user数组即可登录的方法, 多用于插件等特殊场合”,直接调用 $this->user->simpleLogin($uid),即可登录成功。只要思想不滑坡,方法总比困难多。 -
PostgreSQL:Unsupported binary encoding of timestamp. 报错信息服务启动后的前几次查询没有问题,多次查询后报这个错。org.postgresql.util.PSQLException:Unsupported binary encoding of timestamp.报错原因PostgreSql默认使用二进制进行数据的传输,导致的jdbc解析失败。解决方案数据库连接信息中配置不使用二进制传输 binaryTransfer=falsejdbc:postgresql://localhost:5432/test?binaryTransfer=false
-
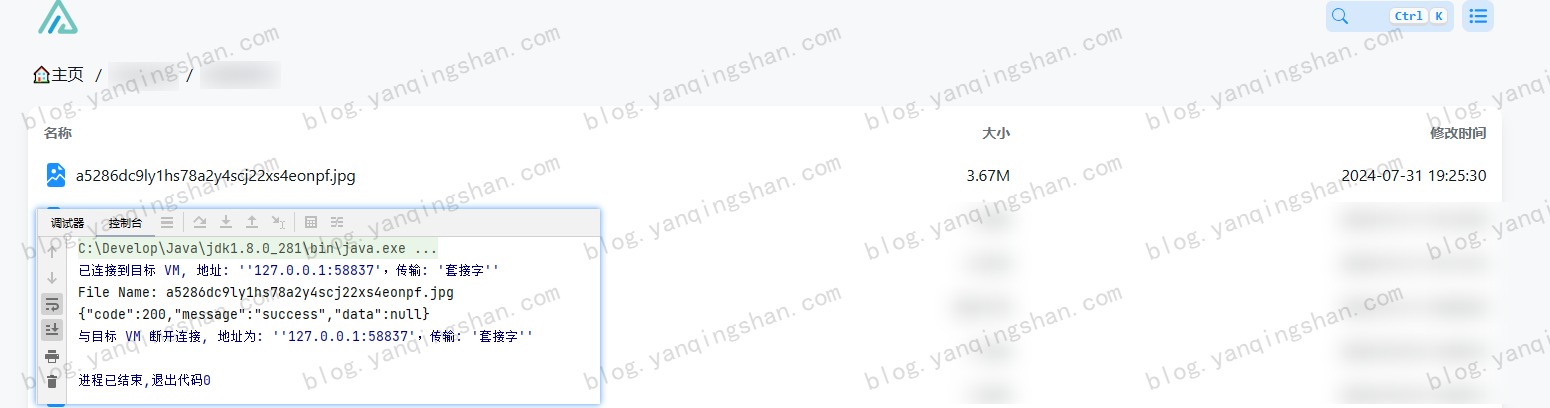
代码实现:微博图片转存AList 最近想把之前我存在微博的图片转入 AList 中,发现有点问题,原因是微博开启防盗链,无法直接在浏览器中打开或直接拿到文件流,这就造成 AList 无法通过离线下载。原因分析微博图床开启防盗链,所以需要在请求头中携带 Referer ,这样才能获取到流数据。AList 也提供了三方接口,可以自己调用上传文件。详见:AList API文档代码实现上面的常量配置自己的 Alist 信息就可以了,主要是 域名、账号、密码以及上传路径package com.yanqingshan.blog; import cn.hutool.http.ContentType; import cn.hutool.http.Header; import cn.hutool.http.HttpRequest; import cn.hutool.http.HttpResponse; import cn.hutool.json.JSONUtil; import java.util.HashMap; import java.util.Map; /** * 微博上传Alist简单测试 * * @author yanqs * @since 2024-07-31 */ public class WeiBoImgDemo { /** * USER_AGENT */ private static final String USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"; /** * Alist 域名 */ private static final String BASE_URL = ""; /** * Alist 账号 */ private static final String USER_NAME = ""; /** * Alist 密码 */ private static final String PASSWORD = ""; /** * Alist 上传路径 */ private static final String UPLOAD_Path = ""; public static void main(String[] args) { String url = "https://tvax3.sinaimg.cn/large/a5286dc9ly1hs78a2y4scj22xs4eonpf.jpg"; int lastSlashIndex = url.lastIndexOf('/'); // 如果找到了斜杠,就从斜杠后面截取字符串 String fileName = url.substring(lastSlashIndex + 1); System.out.println("File Name: " + fileName); HttpRequest request = HttpRequest.get(url) .header(Header.REFERER, "https://weibo.com/")//头信息,多个头信息多次调用此方法即可 .header(Header.USER_AGENT, USER_AGENT) .timeout(20000); HttpResponse httpResponse = request.executeAsync(); // 获取到文件流 上传到Alist byte[] bytes = httpResponse.bodyBytes(); String result = HttpRequest.put(BASE_URL + "/api/fs/put") .header(Header.AUTHORIZATION, getToken()) .header(Header.CONTENT_TYPE, ContentType.MULTIPART.getValue()) .header("File-Path", UPLOAD_Path + fileName) .body(bytes) .execute().body(); System.out.println(result); } /** * 获取Alist Token * * @return */ public static String getToken() { Map<String, String> params = new HashMap<>(); params.put("username", USER_NAME); params.put("password", PASSWORD); String body = HttpRequest.post(BASE_URL + "/api/auth/login") .header(Header.CONTENT_TYPE, ContentType.JSON.getValue()) .body(JSONUtil.toJsonStr(params)) .execute().body(); return JSONUtil.parseObj(body).getJSONObject("data").getStr("token"); } }注:其中微博图片的链接有多种可选large -> 原始图片oslarge ->无水印 mw690 -> 最大 690 像素宽度裁剪thumbnail -> 缩略图small -> 小图square -> 80 像素正方形裁剪thumb150 -> 150 像素正方形裁剪thumb180 -> 180 像素正方形裁剪thumb300 -> 300 像素正方形裁剪orj180 -> 180 像素宽度原比例缩放orj360 -> 360 像素宽度原比例缩放运行结果运行效果如下后续可以自己建一个txt文件,将微博图片的后缀存起来,然后把上面代码改造一下就可以实现。
-
-
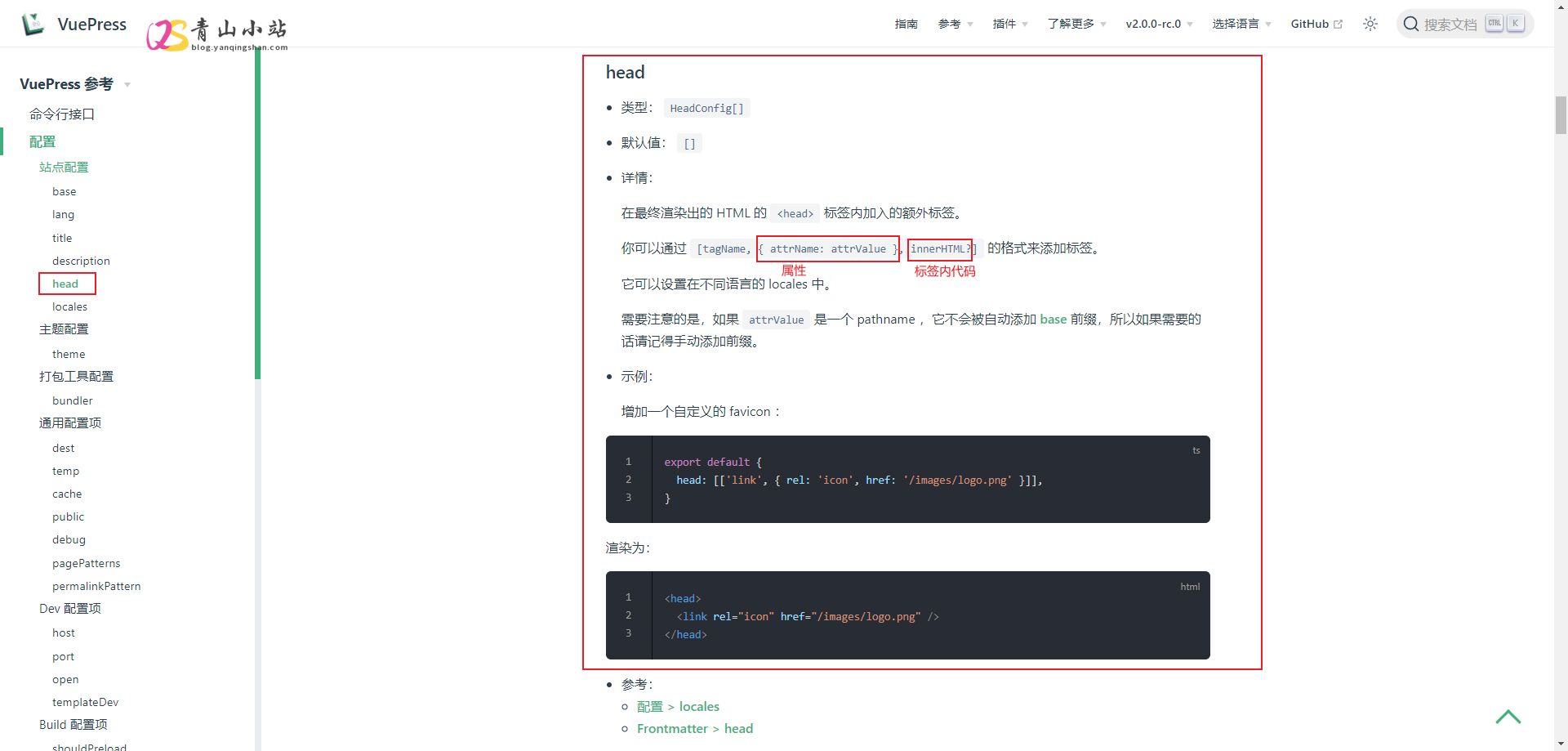
VuePress 配置51LA/统计鸟统计代码 自从 语雀 付费和异常后,我也急需一款 Wiki知识手册 ,考虑了Hexo、GitBook、Docsify 等,感觉都各自有优缺点,最后选择了VuePress 2.0.0 搭建属于自己的私有化 Wiki知识手册 。使用过程中都还比较顺利,但是突然间发现跟其他 Vue 项目有点不太一样,少了一个 index.html ,这样不能在全局文件中引用/配置统计代码,刚好晚上在写知识手册的时候,看了一眼官方的说明文档,然后分享了一下统计代码,终于配置出来了。在全局 config.js 配置文件 head 参数中添加,就最终渲染出的 HTML 的 <head> 标签内加入的额外标签。但是之前一直添加不成功,后来分析了一下参数,这里以51LA为例。图上标注的红色就相当于红和绿就相当于第二个参数 { attrName: attrValue } ,而黄色就相当于最后一个参数 innerHTML? 那这样分析后,我们就可以这样写。head: [ ['script',{type:'text/javascript',src:'https://api.tongjiniao.com/c?_=***',async:''}], ['script',{charset:'UTF-8',id:'LA_COLLECT',src:'https://sdk.51.la/js-sdk-pro.min.js'}], ['script',{},'LA.init({id:"*****",ck:"*****",autoTrack:true,hashMode:true})'], ['script',{src: 'https://sdk.51.la/perf/js-sdk-perf.min.js',crossorigin:'anonymous'}], ['script',{},'new LingQue.Monitor().init({id:"******",sendSuspicious:true,sendSpaPv:true});'] ]第一个数组是统计鸟的,第二三数组是51LA的,第三四数组是51LA灵雀应用监控平台的。(注:其中官方的参数均使用**代替)至此,统计代码就安装完成了,如果要在 head 中引用其他脚本,也可以参考这样的写法。
-
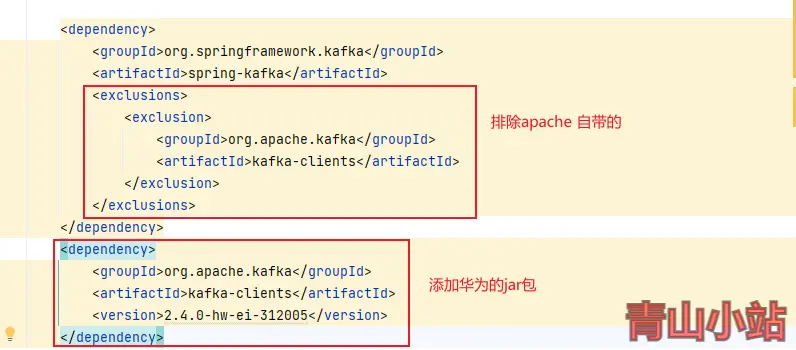
SpringBoot 对接华为大数据平台kerberos认证的Kafka数据 最近项目中有用到kafka来同步某业务核心数据,通过kafka来进行数据的实时更新。原本使用的是Apache kafka 来进行订阅消费,后因业务方信创要求,更换了华为大数据平台的Kafka数据源,采用kerberos认证。对接了一天多,数据才接入成功,网上相关文档比较少,这里我总结一下,为后人少踩坑。本次使用的是华为MRS3.1.2版本,其他版本应该都类似。修改项目中的pom.xml依赖,将默认的apache的kafka-client包替换为华为自带的。如果拉去不到相关依赖包,请更换为华为Maven镜像,配置信息如下。<repositories> <repository> <id>huawei-cloud-sdk</id> <name>HuaWei Cloud Mirrors</name> <url>https://mirrors.huaweicloud.com/repository/maven/huaweicloudsdk/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>true</enabled> </snapshots> </repository> <repository> <id>huawei-mirrors</id> <name>HuaWei Mirrors</name> <url>https://repo.huaweicloud.com/repository/maven/</url> </repository> </repositories>我们需要在配置文件中增加新的配置文件,不要使用spring.kafka相关配置,建议自己新增一个配置信息,本文以huawei.mrs.kafka为例。huawei: mrs: kafka: enable: false bootstrap-servers: 10.244.231.2:21007,10.244.230.202:21007,10.244.230.125:21007 security: protocol: SASL_PLAINTEXT kerberos: domain: name: hadoop.hadoop_651_arm.com sasl: kerberos: service: name: kafka新建一个配置文件HuaWeiMrsKafkaConfiguration,配置相关信息@Value("${huawei.mrs.kafka.enable}") public Boolean enable; @Value("${huawei.mrs.kafka.bootstrap-servers}") public String boostrapServers; @Value("${huawei.mrs.kafka.security.protocol}") public String securityProtocol; @Value("${huawei.mrs.kafka.kerberos.domain.name}") public String kerberosDomainName; @Value("${huawei.mrs.kafka.sasl.kerberos.service.name}") public String kerberosServiceName; @Bean public ConcurrentKafkaListenerContainerFactory<?, ?> kafkaListenerContainerFactory( ConcurrentKafkaListenerContainerFactoryConfigurer configurer, ConsumerFactory<Object, Object> kafkaConsumerFactory, KafkaTemplate<String, String> template) { ConcurrentKafkaListenerContainerFactory<Object, Object> factory = new ConcurrentKafkaListenerContainerFactory<>(); configurer.configure(factory, kafkaConsumerFactory); //禁止消费者自启动,达到动态启动消费者的目的 factory.setAutoStartup(enable); return factory; } @Bean public ConsumerFactory<Object, Object> consumerFactory() { Map<String, Object> configs = new HashMap<>(); configs.put("security.protocol", securityProtocol); configs.put("kerberos.domain.name", kerberosDomainName); configs.put("bootstrap.servers", boostrapServers); configs.put("sasl.kerberos.service.name", kerberosServiceName); configs.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); configs.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); return new DefaultKafkaConsumerFactory<>(configs); } @Bean public KafkaTemplate<String, String> kafkaTemplate() { Map<String, Object> configs = new HashMap<>(); configs.put("security.protocol", securityProtocol); configs.put("kerberos.domain.name", kerberosDomainName); configs.put("bootstrap.servers", boostrapServers); configs.put("sasl.kerberos.service.name", kerberosServiceName); configs.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); configs.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); ProducerFactory<String, String> producerFactory = new DefaultKafkaProducerFactory<>(configs); return new KafkaTemplate<>(producerFactory); } @Bean public RecordMessageConverter converter() { return new StringJsonMessageConverter(); }再新建一个全局消费kafka数据的KafkaConsumer类@Slf4j @Component public class KafkaConsumer { @KafkaListener(topics = "topic1") public void topicMessage(ConsumerRecord<?, ?> record) { log.info("Kafka->topic:‘topic1’-->{}", record.value()); //TODO:业务逻辑 } }配置kerberos信息,也是非常重要的一步,配置kerberos认证文件,本文将以最简单的教程为例,在启动脚本中配置。为什么不在项目中配置呢?因为各位的项目都各自不同,放在resources目录中,有的时候会读取不到,所以我们以最简单的例子来作为讲解。打包项目,将打包好的jar放置在服务器中。并将下载安全集群认证用户的krb5.conf和user.keytab文件放置跟jar包相同目录或者自定义一个目录(本文以/data/java/huawei-mrs-kafka为例)。在这个文件夹或者部署目录通缉新建一个jaas.conf文件,将keyTab项修改为绝对路径。principal则是华为大数据平台提供的账号。Client { com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true keyTab="/data/java/huawei-mrs-kafka/user.keytab" principal="developuser@HADOOP_651_ARM.COM" useTicketCache=false storeKey=true debug=true; }; KafkaClient { com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true keyTab="/data/java/huawei-mrs-kafka/user.keytab" principal="developuser@HADOOP_651_ARM.COM" useTicketCache=false storeKey=true debug=true; }; 最后一步,运行jar包,指定krb5.conf和jaas.conf环境变量。java -jar -Djava.security.krb5.conf=/data/java/huawei-mrs-kafka/krb5.conf -Djava.security.auth.login.config=/data/java/huawei-mrs-kafka/jaas.conf huawei-mrs-kafka-1.0-SNAPSHOT.jar因为本地没有相关环境,生产环境又处于内网,这里就不提供相关运行成功的代码,对接华为大数据平台的Kafka其实很简单,只是网上的教程很少而已。如有这方面的问题,可以在本文留言,看到了就会回复。{cloud title="示例下载" type="default" url="https://www.gitlink.org.cn/yanqs/huawei-mrs-kafka-demo" password=""/}
-
使用VuePress搭建Wiki静态网站 最近使用 语雀 做了一个知识手册,改版后只能会员才能分享,想着数据托管到第三方,还不如自建。参考了其他静态网站生成,最后决定使用 VuePress 来搭建。环境要求Node.js v16.19.0+搭建框架步骤 1: 创建并进入一个新目录mkdir wiki-book cd wiki-book步骤 2: 初始化项目npm init步骤 3: 将 VuePress 安装为本地依赖npm install -D vuepress@next步骤 4: 在 package.json 中添加一些 scripts{ "scripts": { "docs:dev": "vuepress dev docs", "docs:build": "vuepress build docs" } }步骤 5: 将默认的临时目录和缓存目录添加到 .gitignore 文件中echo 'node_modules' >> .gitignore echo '.temp' >> .gitignore echo '.cache' >> .gitignore步骤 6: 创建你的第一篇文档mkdir docs echo '# Hello VuePress' > docs/README.md步骤 7: 在本地启动服务器来开发你的文档网站npm run docs:devVuePress 会在 http://localhost:8080 启动一个热重载的开发服务器。当你修改你的 Markdown 文件时,浏览器中的内容也会自动更新。进阶配置启动上面项目后,会在docs 下会生成一个.vuepress 目录,我们在这个目录下创建一个config.js 文件。这个是 VuePress 站点的基本配置文件,在这个里面我们可以配置站点基础信息、插件、主题等。具体可以参考官方文档:配置信息这里我把常用的配置分享一下:import { defineUserConfig } from 'vuepress' //引入默认主题 import { defaultTheme } from '@vuepress/theme-default' export default defineUserConfig({ // 开发服务器的端口号 port: 8080, // 启动后打开浏览器 open: false, // 设置站点根路径 base: '/', // 站点的语言 lang: 'zh-CN', // 站点的标题 title: '知识手册', // 站点的描述 description: '站点的描述', // 默认主题配置 theme: defaultTheme({ // 默认颜色模式 colorMode: 'auto', // 是否启用切换颜色模式的功能 colorModeSwitch: true, // logo Logo 图片的 URL。 //logo: '' // 导航栏配置 navbar:[ ], // 侧边栏配置 sidebar:[ ] }) })打包配置运行 npm run docs:build 生成后的文件在 docs\.vuepress\dist 中,将这个文件压缩丢在服务器中,就可以打开了。一般只要支持 html 的web服务器都是可以的。这里不做过多描述。样例代码{cloud title="样例代码" type="lz" url="https://xiaose.lanzoum.com/b02ewqy8h" password="h39g"/}
-
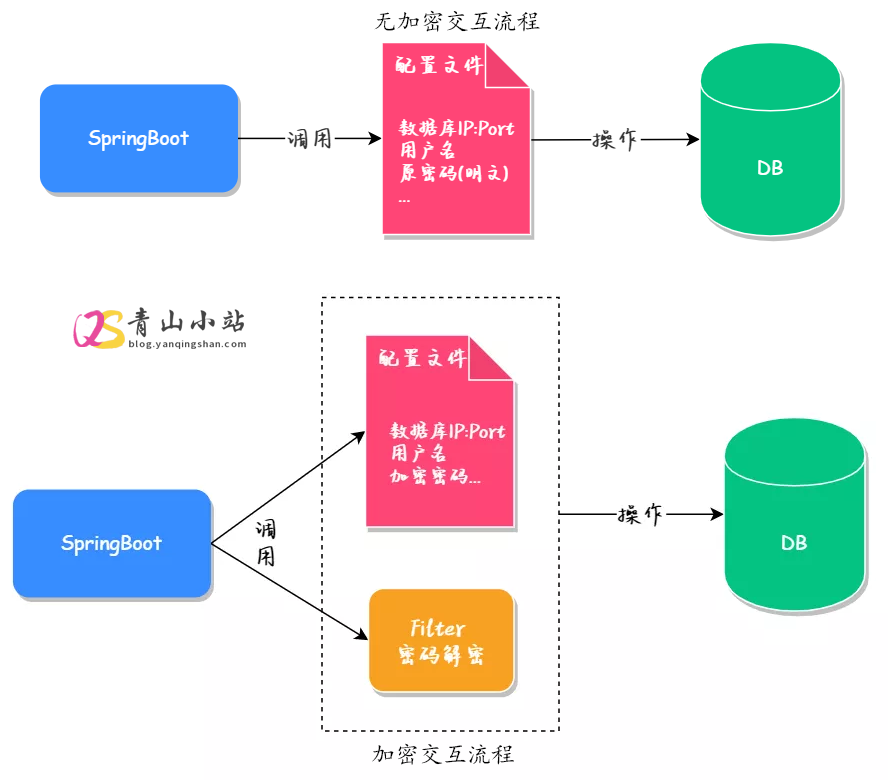
druid连接池实现数据库加密 无论是公司的项目还是个人的项目,我们都会选择将源码上传到 Git 服务器(GitHub、Gitee 或是自建服务器),但只要将源码提交到公网服务器就会存在源码泄漏的风险,而数据库配置信息作为源码的一部分,一旦出现源码泄漏,那么数据库中的所有数据都会公之于众,其产生的不良后果无法预期。于是为了避免这种问题的产生,我们至少要对数据库的密码进行加密操作,这样即使得到了源码,也不会造成数据的泄露。怎么实现加密? 对于 Java 项目来说,要想快速实现数据库的加密,最简单可行的方案就是使用阿里巴巴提供的 Druid 来实现加密。交互流程执行命令这里我们以 1.2.18 版本为例,各位也可以选择其他版本,命令基本都是一样的。 java -cp [druid-1.2.18.jar仓库路径] [com.alibaba.druid.filter.config.ConfigTools] [密码]命令示例java -cp D:\druid\druid-1.2.18.jar com.alibaba.druid.filter.config.ConfigTools 123456 执行结果: privateKey:MIIBVgIBADANBgkqhkiG9w0BAQEFAASCAUAwggE8AgEAAkEAloMI1R+5QNFTDAUvZ5KCkq+qauA2IJbiYR0ghk9ssWm7lPooZEOipCa88W0rya/4oaOt6i0iVlS/EmtmMCTZ7QIDAQABAkEAjWMyXOKcJ+N7XANS8LyUpC8Yq6VLs3mJ1yiBcSoTNORpTxndFog/BXUXQP6yTkNHk+Nc5sxdGvl42y3mywiRAQIhAMhiyFRwWWdImzPR+fC8n6s3+B341jy3AWMrixXMAJydAiEAwEjAp9LTgS0fIoEtlz6KYbVnsionIIof1JKAbsJjKZECIQCuthHcLSiF+LP49nZpAsxjyCS4XSDNRvIauPhHRNqzsQIhAJuBux1+6cLMxSNYqZBp6ex/k2+Jm787Nebq3Ke22g+hAiBi9IOPYlm40BAp9jkr2Z2/yqV1E0ppfqigUbFNIpp79g== publicKey:MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBAJaDCNUfuUDRUwwFL2eSgpKvqmrgNiCW4mEdIIZPbLFpu5T6KGRDoqQmvPFtK8mv+KGjreotIlZUvxJrZjAk2e0CAwEAAQ== password:YJHHitRl6unpzMi4dfxDOUH7R0kSB/32Wxu0D+xRA5ijmmaO8whHSlCAm3iQ9OqtJXwPU/NzcKmGx/QvhRxnHg==截图示例替换配置文件spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver type: com.alibaba.druid.pool.DruidDataSource druid: url: jdbc:mysql://localhost:3306/test?useSSL=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai username: root #生成后的密文 password: YJHHitRl6unpzMi4dfxDOUH7R0kSB/32Wxu0D+xRA5ijmmaO8whHSlCAm3iQ9OqtJXwPU/NzcKmGx/QvhRxnHg== filters: config connect-properties: config.decrypt: true #生成的公钥 config.decrypt.key: MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBAJaDCNUfuUDRUwwFL2eSgpKvqmrgNiCW4mEdIIZPbLFpu5T6KGRDoqQmvPFtK8mv+KGjreotIlZUvxJrZjAk2e0CAwEAAQ==
-
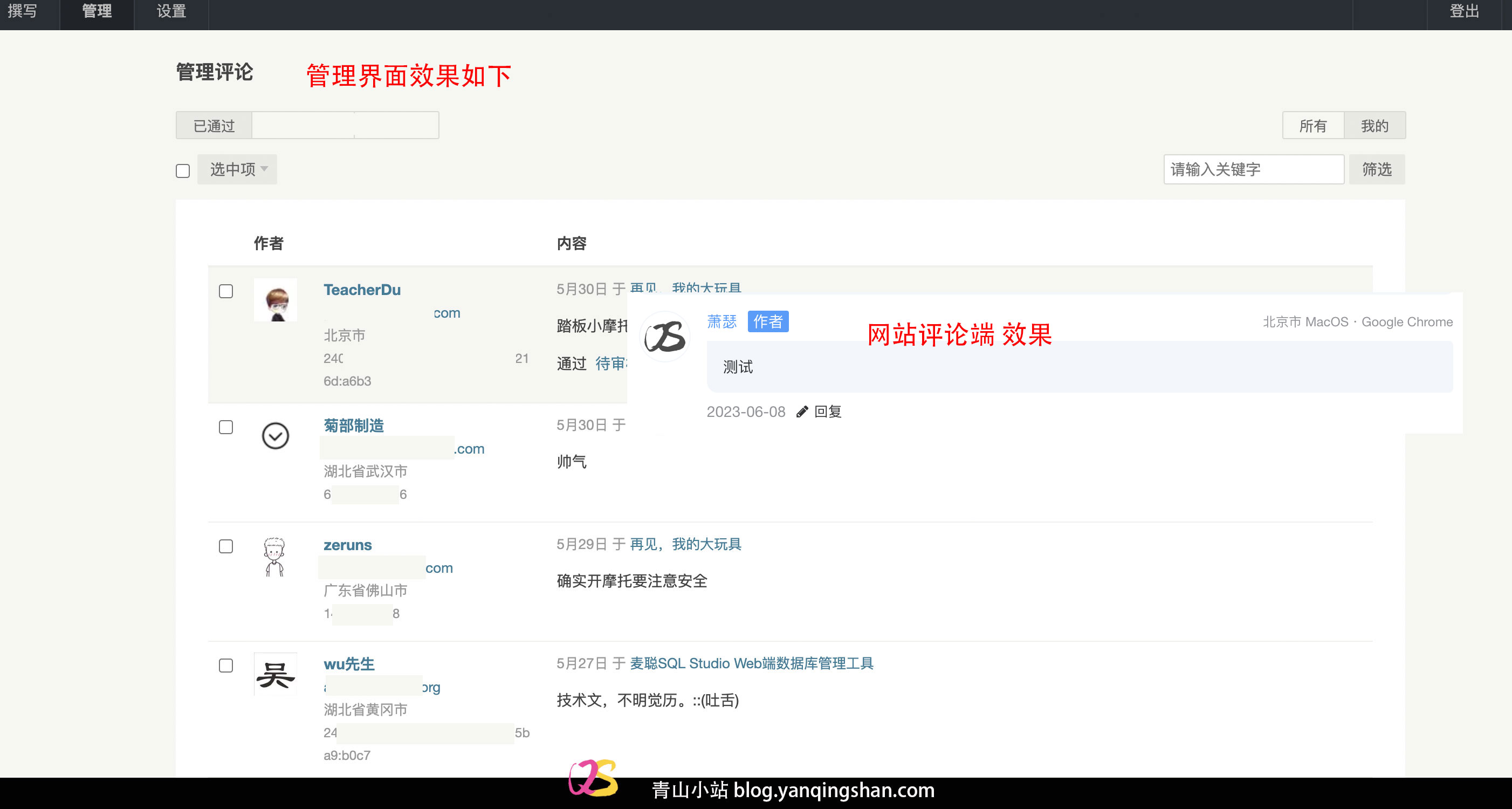
Joe 主题对接腾讯 LBS 展示 IP 属地(二) 书接上回,我们在主题中对接腾讯LBS IP查询服务后,会有一个bug:如果某篇文章评论过多,则某些评论IP定位数据无法显示,这个是因为腾讯LBS服务个人开发者的并发量限制为5次/秒。在上一个教程发布后,也有大佬发现了这个问题,不过这个问题我顺手就解决了,但是解决方案没有分享出来,因为需要改typecho系统的代码。这个已经脱离技术小白的范围,请合理折腾,折腾前记得备份数据。{anote icon="fa-internet-explorer" href="https://blog.yanqingshan.com/130.html" type="success" content="Joe 主题对接腾讯 LBS 展示 IP 属地"/}原理这一次折腾的原理是,我们在数据库中添加一个字段作为IP属地信息的一个冗余信息;当用户评论时,获取用户IP地址,调用腾讯LBS服务进行查询,将查询到的数据写入数据库中,这样就避免并发量超出限制。执行sql语句23.06.10:根据Typecho数据库设计文档又更新了一下sql语句ALTER TABLE `typecho_comments` ADD COLUMN `ipRegion` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT 'IP中文地址' AFTER `parent`, DROP PRIMARY KEY, ADD PRIMARY KEY (`coid`) USING BTREE;上面sql就是在字段coid后增加一个ipRegion的字段,并且添加一个备注信息。修改代码我们打开网站根目录,路径:/var/Widget/Base/Comments.php 这个文件是系统评论对外提供的方法,包括插入数据和查询数据等方法,有能力的同学,可以翻翻代码,基本上面都有注释;大概55行,也就是增加评论 的方法首行,增加以下代码,将key和sign_key修改为自己申请的就可以。$ipRegion = ''; $cip = empty($comment['ip']) ? $this->request->getIp() : $comment['ip']; $key = '配置自己申请的key'; //签名校验的KEY $sign_key = '配置自己申请的sign_key'; $sign = md5('/ws/location/v1/ip?ip='.$cip.'&key='.$key.$sign_key); $url = 'https://apis.map.qq.com/ws/location/v1/ip?ip='.$cip.'&key='.$key.'&sig='.$sign; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_BINARYTRANSFER, 1); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_AUTOREFERER, 1); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); curl_setopt($ch, CURLOPT_HTTPGET, true); curl_setopt($ch, CURLOPT_REFERER, $url); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'); $content = curl_exec($ch); curl_close($ch); if($content) { $json = json_decode($content,true); if($json['status'] == 0 ){ $resjson = $json['result']['ad_info']; if($resjson['nation'] == '中国'){ if($resjson['province']=='北京市'||$resjson['province']=='天津市'||$resjson['province']=='上海市'||$resjson['province']=='重庆市'){ $ipRegion = $resjson['city']; }else{ $ipRegion = $resjson['province'].$resjson['city']; } }else{ $ipRegion = $resjson['nation'].$resjson['province'].$resjson['city'].$resjson['district']; } } }上面代码增加完后,大概在108行,也就是构建插入结构 那行注释里面增加一个参数,把下面代码放在[]中,'ipRegion' => $ipRegion, 在381行后,插入下面,这个就是把查询对象增加一个输出值'table.comments.ipRegion'基本上请求和写入已经完成,我们再改一下后台管理界面,把这个ip属地也添加到页面上,这样后台也方便查询打开admin/manage-comments.php136行后增加以下代码<br /><span><?php $comments->ipRegion(); ?>最后我们再来修改主题的评论,这里以Joe主题为例文件路径joe/public/comment.php<?php $comments->ipRegion(); ?> 找到合适位置显示IP属地,我是放在112行的<div class="agent"> <?php $comments->ipRegion(); ?> <?php _getAgentOS($comments->agent); ?> · <?php _getAgentBrowser($comments->agent); ?> </div>最终效果如下
-
Java 使用JDBC备份数据库中的表和数据 实现思路加载数据库驱动程序并建立数据库连接。使用JDBC API查询需要备份的表格和数据。在输出文件中以适当的格式编写SQL语句来创建表格。用适当的格式编写INSERT语句将行数据写入输出文件。5. 关闭所有数据库连接和输出文件。实现代码package com.yanqingshan.admin.jdbc; import lombok.extern.slf4j.Slf4j; import org.junit.jupiter.api.Test; import org.springframework.boot.test.context.SpringBootTest; import java.io.FileWriter; import java.io.IOException; import java.sql.*; import java.util.ArrayList; import java.util.List; /** * 通过JDBC备份 库表数据 * * @author yanqs * @date 2023年04月28日 9:31 */ @Slf4j @SpringBootTest class BuildSql { @Test void testBuildSql() throws ClassNotFoundException, SQLException, IOException { String dbUrl = "jdbc:mysql://192.168.57.110:3306/boot-startup"; String username = "test"; String password = "123456"; // 加载JDBC驱动程序 Class.forName("com.mysql.cj.jdbc.Driver"); // 建立数据库连接 Connection conn = DriverManager.getConnection(dbUrl, username, password); // 创建Statement对象 Statement stmt = conn.createStatement(); // 查询所有表格名字 ResultSet result = stmt.executeQuery("SHOW TABLES"); // 备份的SQL文件 FileWriter writer = new FileWriter("backup.sql"); // 循环遍历所有表 存表 List<String> tableNameList = new ArrayList<>(); while (result.next()) { tableNameList.add(result.getString(1)); } for (String tableName : tableNameList) { log.info("开始备份“{}”表结构", tableName); // 在输出文件中写入创建表格SQL语句 ResultSet rs = stmt.executeQuery("SHOW CREATE TABLE " + tableName); if (rs.next()) { writer.write("\n\n" + rs.getString(2) + ";\n\n"); } // 循环遍历表格中的所有行来写入数据 rs = stmt.executeQuery("SELECT * FROM " + tableName); int columnCount = rs.getMetaData().getColumnCount(); log.info("开始生成“{}”表数据", tableName); while (rs.next()) { writer.write("INSERT INTO " + tableName + " VALUES ("); for (int i = 1; i <= columnCount; i++) { writer.write("'" + rs.getString(i) + "'"); if (i < columnCount) { writer.write(","); } } writer.write(");\n"); } } // 关闭所有连接 writer.close(); result.close(); stmt.close(); conn.close(); log.info("备份完成"); } }实现效果