搜索到
40
篇与
Java
的结果
-

-
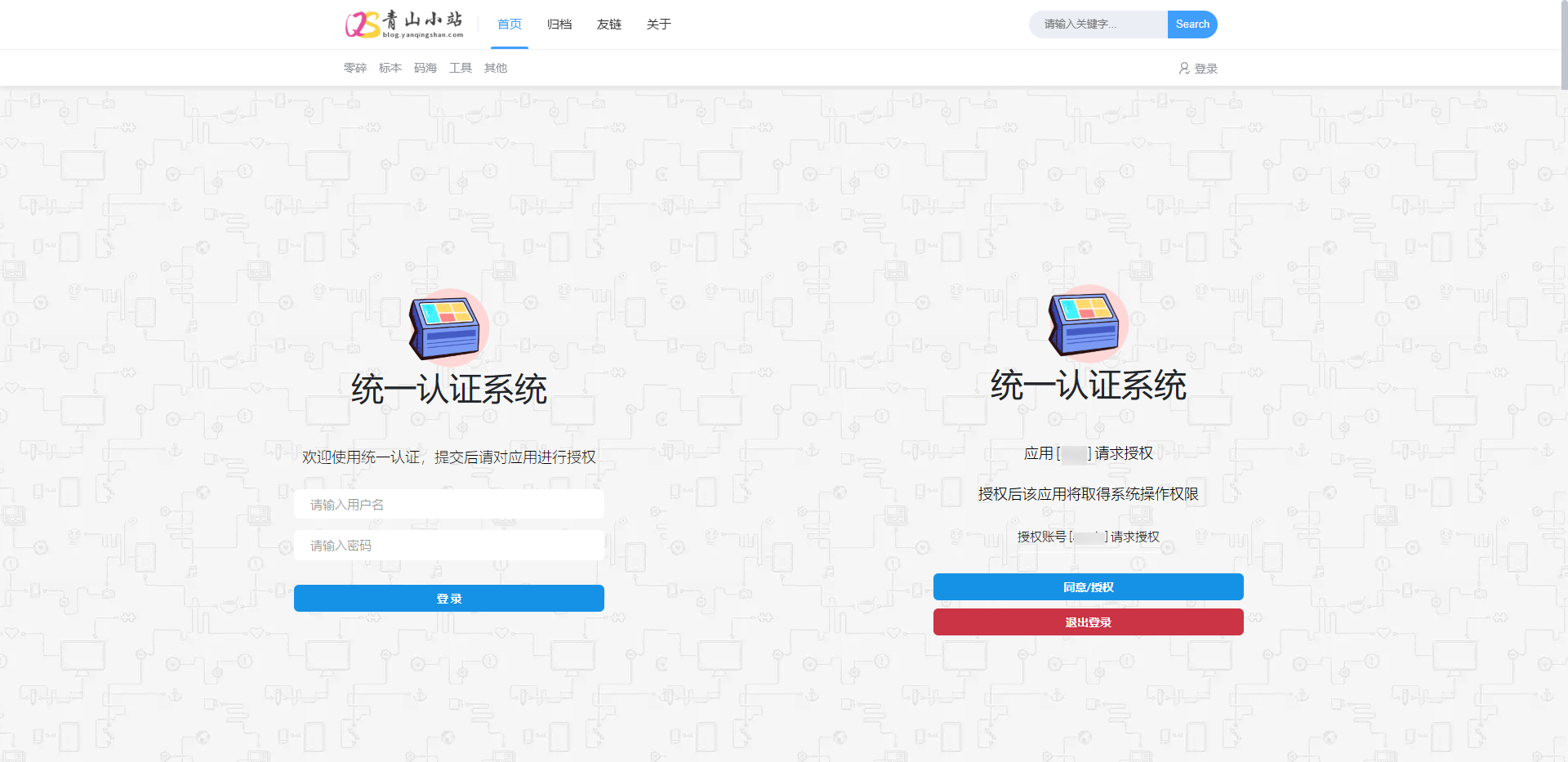
Typecho(1.2.1)免密登录研究笔记 最近在研究 Spring Cloud 微服务 框架,便研究了一下它的OAuth2认证模式,想着在Typecho中也对接下,后面就不用再次输入账号密码了,很是方便。其中技术难点,是 Typecho 的免密登录方式,看到官方文档说的是封装在了Widget_User组件中,开发人员可调用此组件免密登录。但是验证了好久,都无法登录成功,又研究了聚合登录的插件中的免密登录(见下方)方法,也不是很好使。//使用用户uid登录 private function useUidLogin($uid, $expire = 0) { $authCode = function_exists('openssl_random_pseudo_bytes') ? bin2hex(openssl_random_pseudo_bytes(16)) : sha1(Typecho_Common::randString(20)); $user = array('uid'=>$uid,'authCode'=>$authCode); Typecho_Cookie::set('__typecho_uid', $uid, $expire); Typecho_Cookie::set('__typecho_authCode', Typecho_Common::hash($authCode), $expire); //更新最后登录时间以及验证码 $this->db->query($this->db ->update('table.users') ->expression('logged', 'activated') ->rows(array('authCode' => $authCode)) ->where('uid = ?', $uid)); }这个是根据用户的 uid 进行免密登录,但是调用 $this->user->hasLogin() 来判断用户是否登录,一直是 false;查了查资料,看到了一篇《Typecho不改核心代码实现自定义登录、注册功能》文档,然后给了一个思路,研究一下1.2.1版本用户那块的代码;在/var/Widget/User.php中,用户登录跟聚合登录的方式一样,但是就是不好使,再向下有一个方法,叫 simpleLogin; 注解也写的很好“只需要提供uid或者完整user数组即可登录的方法, 多用于插件等特殊场合”,直接调用 $this->user->simpleLogin($uid),即可登录成功。只要思想不滑坡,方法总比困难多。
-
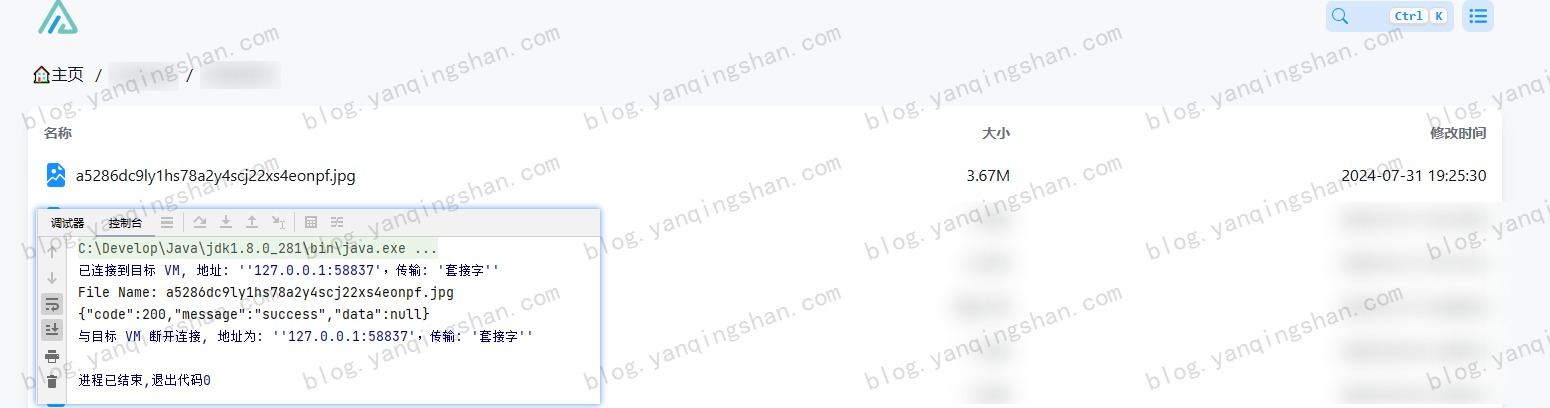
代码实现:微博图片转存AList 最近想把之前我存在微博的图片转入 AList 中,发现有点问题,原因是微博开启防盗链,无法直接在浏览器中打开或直接拿到文件流,这就造成 AList 无法通过离线下载。原因分析微博图床开启防盗链,所以需要在请求头中携带 Referer ,这样才能获取到流数据。AList 也提供了三方接口,可以自己调用上传文件。详见:AList API文档代码实现上面的常量配置自己的 Alist 信息就可以了,主要是 域名、账号、密码以及上传路径package com.yanqingshan.blog; import cn.hutool.http.ContentType; import cn.hutool.http.Header; import cn.hutool.http.HttpRequest; import cn.hutool.http.HttpResponse; import cn.hutool.json.JSONUtil; import java.util.HashMap; import java.util.Map; /** * 微博上传Alist简单测试 * * @author yanqs * @since 2024-07-31 */ public class WeiBoImgDemo { /** * USER_AGENT */ private static final String USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"; /** * Alist 域名 */ private static final String BASE_URL = ""; /** * Alist 账号 */ private static final String USER_NAME = ""; /** * Alist 密码 */ private static final String PASSWORD = ""; /** * Alist 上传路径 */ private static final String UPLOAD_Path = ""; public static void main(String[] args) { String url = "https://tvax3.sinaimg.cn/large/a5286dc9ly1hs78a2y4scj22xs4eonpf.jpg"; int lastSlashIndex = url.lastIndexOf('/'); // 如果找到了斜杠,就从斜杠后面截取字符串 String fileName = url.substring(lastSlashIndex + 1); System.out.println("File Name: " + fileName); HttpRequest request = HttpRequest.get(url) .header(Header.REFERER, "https://weibo.com/")//头信息,多个头信息多次调用此方法即可 .header(Header.USER_AGENT, USER_AGENT) .timeout(20000); HttpResponse httpResponse = request.executeAsync(); // 获取到文件流 上传到Alist byte[] bytes = httpResponse.bodyBytes(); String result = HttpRequest.put(BASE_URL + "/api/fs/put") .header(Header.AUTHORIZATION, getToken()) .header(Header.CONTENT_TYPE, ContentType.MULTIPART.getValue()) .header("File-Path", UPLOAD_Path + fileName) .body(bytes) .execute().body(); System.out.println(result); } /** * 获取Alist Token * * @return */ public static String getToken() { Map<String, String> params = new HashMap<>(); params.put("username", USER_NAME); params.put("password", PASSWORD); String body = HttpRequest.post(BASE_URL + "/api/auth/login") .header(Header.CONTENT_TYPE, ContentType.JSON.getValue()) .body(JSONUtil.toJsonStr(params)) .execute().body(); return JSONUtil.parseObj(body).getJSONObject("data").getStr("token"); } }注:其中微博图片的链接有多种可选large -> 原始图片oslarge ->无水印 mw690 -> 最大 690 像素宽度裁剪thumbnail -> 缩略图small -> 小图square -> 80 像素正方形裁剪thumb150 -> 150 像素正方形裁剪thumb180 -> 180 像素正方形裁剪thumb300 -> 300 像素正方形裁剪orj180 -> 180 像素宽度原比例缩放orj360 -> 360 像素宽度原比例缩放运行结果运行效果如下后续可以自己建一个txt文件,将微博图片的后缀存起来,然后把上面代码改造一下就可以实现。
-
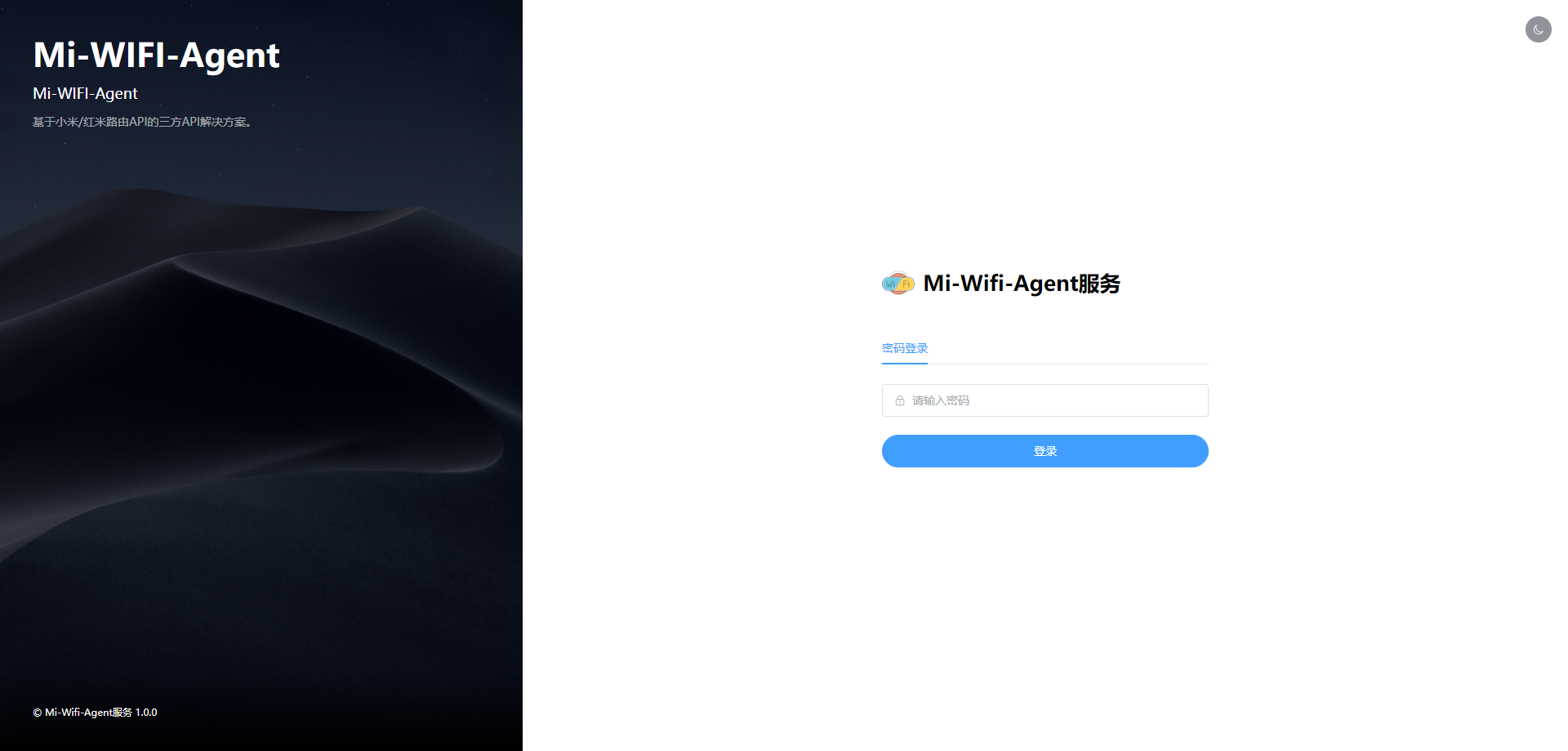
小米/红米路由器Agent 服务正式上线 最近发现家里的路由器,每次配置还需要组网,然后登录管理页面,想着弄一个Agent服务,通过Agent 服务来管理路由器的端口映射,后期还可以对接到我的统管平台中去。在内网的服务器中,部署一个docker镜像,通过容器中的Agent服务对路由器的API接口进行转发,目前1.0.0版本,只做了一个简单的路由器状态查看和端口映射管理。部署docker pull bcrjl/miwifi-agent:latestdocker run -d --name miwifi-agent \ --restart always \ -p 24317:24317 \ -e BMW_URL=192.168.31.1 \ -e BMW_PASSWORD=123456 \ -e WEB_PASSWORD=123456 \ miwifi-agent:latest阿里云镜像docker pull registry.cn-hangzhou.aliyuncs.com/bcrjl/miwifi-agent:latestdocker run -d --name miwifi-agent \ --restart always \ -p 24317:24317 \ -e BMW_URL=192.168.31.1 \ -e BMW_PASSWORD=123456 \ -e WEB_PASSWORD=123456 \ miwifi-agent:latest其中BMW_URL指路由器IP地址,BMW_PASSWORD指路由器密码,WEB_PASSWORD 平台设置的密码。运行成功后访问 http://[IP]:24317运行效果项目地址https://github.com/bcrjl/miwifi-agent如果有想一起维护的小伙伴,可以联系我。
-
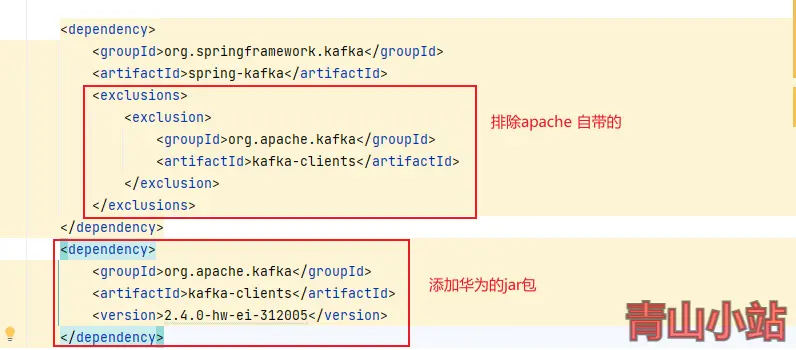
SpringBoot 对接华为大数据平台kerberos认证的Kafka数据 最近项目中有用到kafka来同步某业务核心数据,通过kafka来进行数据的实时更新。原本使用的是Apache kafka 来进行订阅消费,后因业务方信创要求,更换了华为大数据平台的Kafka数据源,采用kerberos认证。对接了一天多,数据才接入成功,网上相关文档比较少,这里我总结一下,为后人少踩坑。本次使用的是华为MRS3.1.2版本,其他版本应该都类似。修改项目中的pom.xml依赖,将默认的apache的kafka-client包替换为华为自带的。如果拉去不到相关依赖包,请更换为华为Maven镜像,配置信息如下。<repositories> <repository> <id>huawei-cloud-sdk</id> <name>HuaWei Cloud Mirrors</name> <url>https://mirrors.huaweicloud.com/repository/maven/huaweicloudsdk/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>true</enabled> </snapshots> </repository> <repository> <id>huawei-mirrors</id> <name>HuaWei Mirrors</name> <url>https://repo.huaweicloud.com/repository/maven/</url> </repository> </repositories>我们需要在配置文件中增加新的配置文件,不要使用spring.kafka相关配置,建议自己新增一个配置信息,本文以huawei.mrs.kafka为例。huawei: mrs: kafka: enable: false bootstrap-servers: 10.244.231.2:21007,10.244.230.202:21007,10.244.230.125:21007 security: protocol: SASL_PLAINTEXT kerberos: domain: name: hadoop.hadoop_651_arm.com sasl: kerberos: service: name: kafka新建一个配置文件HuaWeiMrsKafkaConfiguration,配置相关信息@Value("${huawei.mrs.kafka.enable}") public Boolean enable; @Value("${huawei.mrs.kafka.bootstrap-servers}") public String boostrapServers; @Value("${huawei.mrs.kafka.security.protocol}") public String securityProtocol; @Value("${huawei.mrs.kafka.kerberos.domain.name}") public String kerberosDomainName; @Value("${huawei.mrs.kafka.sasl.kerberos.service.name}") public String kerberosServiceName; @Bean public ConcurrentKafkaListenerContainerFactory<?, ?> kafkaListenerContainerFactory( ConcurrentKafkaListenerContainerFactoryConfigurer configurer, ConsumerFactory<Object, Object> kafkaConsumerFactory, KafkaTemplate<String, String> template) { ConcurrentKafkaListenerContainerFactory<Object, Object> factory = new ConcurrentKafkaListenerContainerFactory<>(); configurer.configure(factory, kafkaConsumerFactory); //禁止消费者自启动,达到动态启动消费者的目的 factory.setAutoStartup(enable); return factory; } @Bean public ConsumerFactory<Object, Object> consumerFactory() { Map<String, Object> configs = new HashMap<>(); configs.put("security.protocol", securityProtocol); configs.put("kerberos.domain.name", kerberosDomainName); configs.put("bootstrap.servers", boostrapServers); configs.put("sasl.kerberos.service.name", kerberosServiceName); configs.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); configs.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); return new DefaultKafkaConsumerFactory<>(configs); } @Bean public KafkaTemplate<String, String> kafkaTemplate() { Map<String, Object> configs = new HashMap<>(); configs.put("security.protocol", securityProtocol); configs.put("kerberos.domain.name", kerberosDomainName); configs.put("bootstrap.servers", boostrapServers); configs.put("sasl.kerberos.service.name", kerberosServiceName); configs.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); configs.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); ProducerFactory<String, String> producerFactory = new DefaultKafkaProducerFactory<>(configs); return new KafkaTemplate<>(producerFactory); } @Bean public RecordMessageConverter converter() { return new StringJsonMessageConverter(); }再新建一个全局消费kafka数据的KafkaConsumer类@Slf4j @Component public class KafkaConsumer { @KafkaListener(topics = "topic1") public void topicMessage(ConsumerRecord<?, ?> record) { log.info("Kafka->topic:‘topic1’-->{}", record.value()); //TODO:业务逻辑 } }配置kerberos信息,也是非常重要的一步,配置kerberos认证文件,本文将以最简单的教程为例,在启动脚本中配置。为什么不在项目中配置呢?因为各位的项目都各自不同,放在resources目录中,有的时候会读取不到,所以我们以最简单的例子来作为讲解。打包项目,将打包好的jar放置在服务器中。并将下载安全集群认证用户的krb5.conf和user.keytab文件放置跟jar包相同目录或者自定义一个目录(本文以/data/java/huawei-mrs-kafka为例)。在这个文件夹或者部署目录通缉新建一个jaas.conf文件,将keyTab项修改为绝对路径。principal则是华为大数据平台提供的账号。Client { com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true keyTab="/data/java/huawei-mrs-kafka/user.keytab" principal="developuser@HADOOP_651_ARM.COM" useTicketCache=false storeKey=true debug=true; }; KafkaClient { com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true keyTab="/data/java/huawei-mrs-kafka/user.keytab" principal="developuser@HADOOP_651_ARM.COM" useTicketCache=false storeKey=true debug=true; }; 最后一步,运行jar包,指定krb5.conf和jaas.conf环境变量。java -jar -Djava.security.krb5.conf=/data/java/huawei-mrs-kafka/krb5.conf -Djava.security.auth.login.config=/data/java/huawei-mrs-kafka/jaas.conf huawei-mrs-kafka-1.0-SNAPSHOT.jar因为本地没有相关环境,生产环境又处于内网,这里就不提供相关运行成功的代码,对接华为大数据平台的Kafka其实很简单,只是网上的教程很少而已。如有这方面的问题,可以在本文留言,看到了就会回复。{cloud title="示例下载" type="default" url="https://www.gitlink.org.cn/yanqs/huawei-mrs-kafka-demo" password=""/}
-
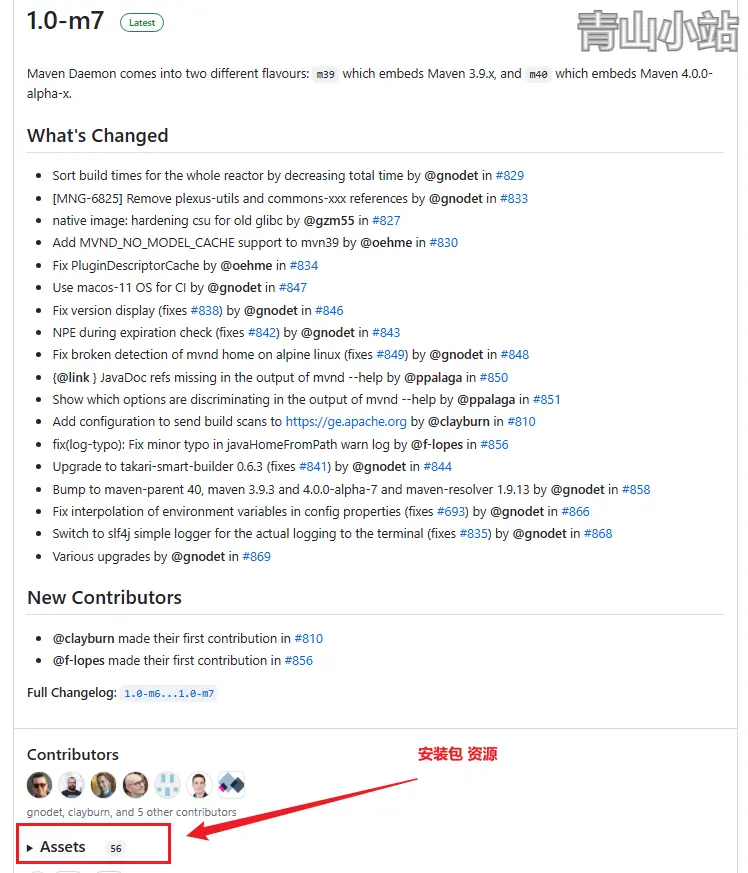
Maven构建工具mvnd和mvn 性能对比测试 最近在技术相关公众号上看到一款 Maven 强化工具 maven-mvnd ,说是 性能 提升 300%,抱着学习的态度来实验一下新技术。Maven-mvnd简介maven-mvnd 是 Apache Maven 团队借鉴了Gradle和Takari的优点,衍生出来的更快的构建工具,maven 的 强化版。maven-mvnd 基于 maven 的但比它更快的构建工具.maven-mvnd 在设计上,使用一个或多个守护进程来构建服务,以此来达到并行的目的!同时,maven-mvnd 内置了maven,因此我可以在maven 过渡到 maven-mvnd的过程中实现 无缝切换!不必再安装 maven 或进行复杂的配置更改。官方仓库地址:https://github.com/apache/maven-mvnd安装步骤GitHub下载压缩包访问仓库版本地址:https://github.com/apache/maven-mvnd/releases点击Assets找到对应的系统的安装包,我们是windows系统,这里以windows为例。基本上就是后缀为windows-amd64.zip的文件,将下载的zip包放置在本地开发目录下,解压文件。修改Windows系统环境变量。编辑 PATH 的环境变量,里面增加 maven-mvnd 的目录。配置环境变量是为了在 cmd 的任意地址,可以识别到 bin 下的 mvnd 命令我们打开cmd命令提示符,输入 mvnd -version 或者 mvnd -v 查看版本信息。输出以下信息,代表安装成功!使用命令mvnd 与 maven 命令几乎没有任何不同,可以通过查看mvnd -help 查看举个例子、如要打包安装,则把 mvn clean install 替换为 mvnd clean install 即可配置可以修改 mvnd 解压目录下 conf 里的 mvnd.properties 文件,拉到最后面,放开 maven.setting 注释,把值改成自己的maven仓库地址即可,如下maven.settings=C://Develop//apache//maven//3.6.3//conf//settings.xml到此配置已经完成。打包速度对比使用一个普通 Java 项目来实验对比,分别使用 maven 和 maven-mvnd 进行打包。# maven 打包命令 mvn clean package -DskipTests # mvnd 打包命令 mvnd clean package -DskipTests结果如下,速度有所提升,速度提升没有网上传言的 8 倍、300%那么夸张,当然,这可能与我的机器或项目有关,你们可以使用你们的项目另行验证!
-
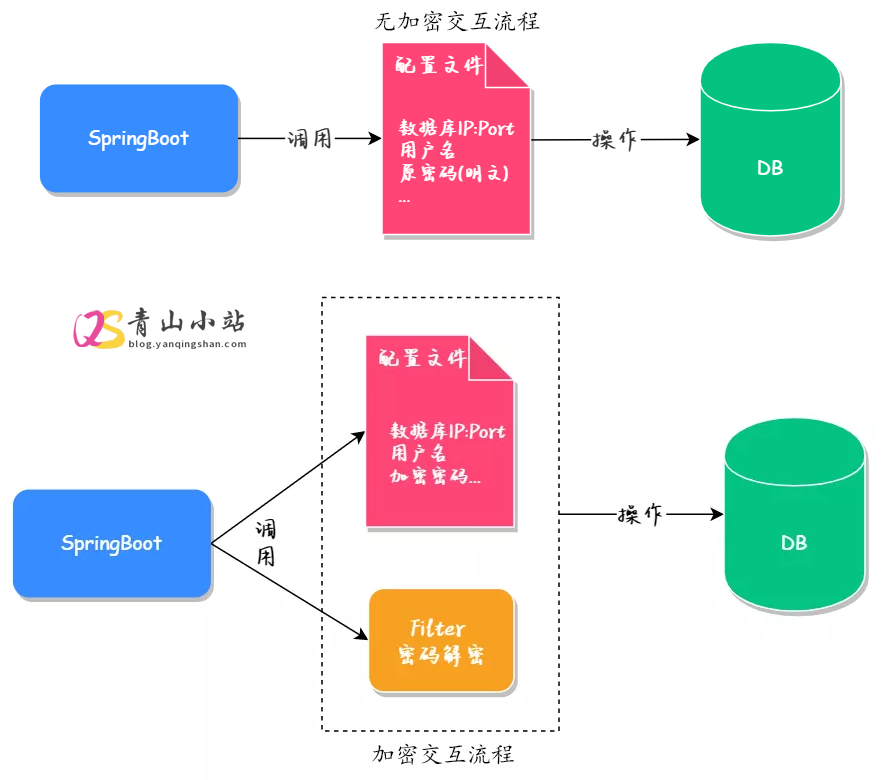
druid连接池实现数据库加密 无论是公司的项目还是个人的项目,我们都会选择将源码上传到 Git 服务器(GitHub、Gitee 或是自建服务器),但只要将源码提交到公网服务器就会存在源码泄漏的风险,而数据库配置信息作为源码的一部分,一旦出现源码泄漏,那么数据库中的所有数据都会公之于众,其产生的不良后果无法预期。于是为了避免这种问题的产生,我们至少要对数据库的密码进行加密操作,这样即使得到了源码,也不会造成数据的泄露。怎么实现加密? 对于 Java 项目来说,要想快速实现数据库的加密,最简单可行的方案就是使用阿里巴巴提供的 Druid 来实现加密。交互流程执行命令这里我们以 1.2.18 版本为例,各位也可以选择其他版本,命令基本都是一样的。 java -cp [druid-1.2.18.jar仓库路径] [com.alibaba.druid.filter.config.ConfigTools] [密码]命令示例java -cp D:\druid\druid-1.2.18.jar com.alibaba.druid.filter.config.ConfigTools 123456 执行结果: privateKey:MIIBVgIBADANBgkqhkiG9w0BAQEFAASCAUAwggE8AgEAAkEAloMI1R+5QNFTDAUvZ5KCkq+qauA2IJbiYR0ghk9ssWm7lPooZEOipCa88W0rya/4oaOt6i0iVlS/EmtmMCTZ7QIDAQABAkEAjWMyXOKcJ+N7XANS8LyUpC8Yq6VLs3mJ1yiBcSoTNORpTxndFog/BXUXQP6yTkNHk+Nc5sxdGvl42y3mywiRAQIhAMhiyFRwWWdImzPR+fC8n6s3+B341jy3AWMrixXMAJydAiEAwEjAp9LTgS0fIoEtlz6KYbVnsionIIof1JKAbsJjKZECIQCuthHcLSiF+LP49nZpAsxjyCS4XSDNRvIauPhHRNqzsQIhAJuBux1+6cLMxSNYqZBp6ex/k2+Jm787Nebq3Ke22g+hAiBi9IOPYlm40BAp9jkr2Z2/yqV1E0ppfqigUbFNIpp79g== publicKey:MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBAJaDCNUfuUDRUwwFL2eSgpKvqmrgNiCW4mEdIIZPbLFpu5T6KGRDoqQmvPFtK8mv+KGjreotIlZUvxJrZjAk2e0CAwEAAQ== password:YJHHitRl6unpzMi4dfxDOUH7R0kSB/32Wxu0D+xRA5ijmmaO8whHSlCAm3iQ9OqtJXwPU/NzcKmGx/QvhRxnHg==截图示例替换配置文件spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver type: com.alibaba.druid.pool.DruidDataSource druid: url: jdbc:mysql://localhost:3306/test?useSSL=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai username: root #生成后的密文 password: YJHHitRl6unpzMi4dfxDOUH7R0kSB/32Wxu0D+xRA5ijmmaO8whHSlCAm3iQ9OqtJXwPU/NzcKmGx/QvhRxnHg== filters: config connect-properties: config.decrypt: true #生成的公钥 config.decrypt.key: MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBAJaDCNUfuUDRUwwFL2eSgpKvqmrgNiCW4mEdIIZPbLFpu5T6KGRDoqQmvPFtK8mv+KGjreotIlZUvxJrZjAk2e0CAwEAAQ==
-
Java 使用JDBC备份数据库中的表和数据 实现思路加载数据库驱动程序并建立数据库连接。使用JDBC API查询需要备份的表格和数据。在输出文件中以适当的格式编写SQL语句来创建表格。用适当的格式编写INSERT语句将行数据写入输出文件。5. 关闭所有数据库连接和输出文件。实现代码package com.yanqingshan.admin.jdbc; import lombok.extern.slf4j.Slf4j; import org.junit.jupiter.api.Test; import org.springframework.boot.test.context.SpringBootTest; import java.io.FileWriter; import java.io.IOException; import java.sql.*; import java.util.ArrayList; import java.util.List; /** * 通过JDBC备份 库表数据 * * @author yanqs * @date 2023年04月28日 9:31 */ @Slf4j @SpringBootTest class BuildSql { @Test void testBuildSql() throws ClassNotFoundException, SQLException, IOException { String dbUrl = "jdbc:mysql://192.168.57.110:3306/boot-startup"; String username = "test"; String password = "123456"; // 加载JDBC驱动程序 Class.forName("com.mysql.cj.jdbc.Driver"); // 建立数据库连接 Connection conn = DriverManager.getConnection(dbUrl, username, password); // 创建Statement对象 Statement stmt = conn.createStatement(); // 查询所有表格名字 ResultSet result = stmt.executeQuery("SHOW TABLES"); // 备份的SQL文件 FileWriter writer = new FileWriter("backup.sql"); // 循环遍历所有表 存表 List<String> tableNameList = new ArrayList<>(); while (result.next()) { tableNameList.add(result.getString(1)); } for (String tableName : tableNameList) { log.info("开始备份“{}”表结构", tableName); // 在输出文件中写入创建表格SQL语句 ResultSet rs = stmt.executeQuery("SHOW CREATE TABLE " + tableName); if (rs.next()) { writer.write("\n\n" + rs.getString(2) + ";\n\n"); } // 循环遍历表格中的所有行来写入数据 rs = stmt.executeQuery("SELECT * FROM " + tableName); int columnCount = rs.getMetaData().getColumnCount(); log.info("开始生成“{}”表数据", tableName); while (rs.next()) { writer.write("INSERT INTO " + tableName + " VALUES ("); for (int i = 1; i <= columnCount; i++) { writer.write("'" + rs.getString(i) + "'"); if (i < columnCount) { writer.write(","); } } writer.write(");\n"); } } // 关闭所有连接 writer.close(); result.close(); stmt.close(); conn.close(); log.info("备份完成"); } }实现效果
-
Java+Selenium学习笔记 Selenium介绍Selenium是一个用于Web应用程序自动化测试工具,背后有google 维护源代码,支持全部主流浏览器,支持主流的编程语言,包括:java,Python,C#,PHP,Ruby等特点开源、免费多浏览器支持:FireFox、Chrome、IE、Opera、Edge;多平台支持:Linux、Windows、MAC;多语言支持:Java、Python、Ruby、C#、JavaScript、C++;对Web页面有良好的支持;简单(API 简单)、灵活(用开发语言驱动);支持分布式测试用例执行。chromeDriver驱动下载:http://chromedriver.storage.googleapis.com/index.html下载的驱动要和自己安装的谷歌浏览器版本相互匹配项目依赖包最新版可以在mvnrepository查找,链接如下<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java --> <dependency> <groupId>org.seleniumhq.selenium</groupId> <artifactId>selenium-java</artifactId> <version>${selenium.version }</version> </dependency> 使用手册1 导航1.1 打开网页driver.get("https://www.baidu.com") driver.navigate.to("https://www.baidu.com") // 区别:get是有逻辑的跳转,而navigate.to是直接跳转到该页面,没有任何逻辑 // 参考:https://blog.csdn.net/gaokao2011/article/details/171699691.2 获取当前页面url//返回的是字符串 String url = driver.getCurrentUrl(); //https://www.baidu.com System.out.println(url); 1.3 返回上一页driver.navigate.back();1.4 前进下一页面driver.navigate.forward();1.5 刷新当前页面driver.navigate.refresh();1.6 获取当前页面的titleString title = driver.getTitle(); //返回字符串 System.out.println(title); //百度一下,你就知道2 窗口、Tabs当driver打开一个新窗口时,若想操作新窗口上的元素,则需要将driver切换到新窗口2.1 获取当前窗口句柄//返回字符串 String currentWindowHandle = driver.getWindowHandle();2.2 获取所有窗口句柄//返回字符串集合 Set<String> allWindowHandles = driver.getWindowHandles(); 2.3 切换到新窗口//newHandle为要切换的新窗口的句柄 driver.switchTo().window(newHandle); 2.4 关闭窗口或tabsdriver.close();2.5 会话结束时退出浏览器driver.quit();3 Frames and IFrames当页面上有iframe和frame元素时,若想操作iframe和frame下的html元素,则需要切换driver3.1 切换到指定iframe或frameWebElement element_iframe = driver.findElement(By.id("iframe1")); driver.switchTo().frame(element_iframe);3.2 切换回父页面driver.switchTo().defaultContent();4 window管理4.1 获取窗口大小int width = driver.manage().window().getSize().getWidth(); int height = driver.manage().window().getSize().getHeight(); Dimension size = driver.manage().window().getSize(); int width = size.getWidth(); int height = size.getHeight();4.2 设置窗口大小driver.manage().window().setSize(new Dimension(1024,768));4.3 获取窗口位置int x = driver.manage().window().getPosition().getX(); int y = driver.manage().window().getPosition().getY(); Point position = driver.manage().window().getPosition(); int x = position.getX(); int y = position.getY();5 设置窗口5.1 设置窗口位置driver.manage().window().setPositon(new Point(0,0));5.2 最大化窗口driver.manage().window().maximize();5.3 全屏窗口driver.manage().window().fullscreen();6 定位driver.find 或 element.findfindElement(By.id("XXX")) findElement(By.name("XXX")) findElement(By.className("XXX")) findElement(By.cssSelector("XXX")) findElement(By.linkText("XXX")) findElement(By.partialLinkText("XXX")) findElement(By.tagName("XXX")) findElement(By.xpath("XXX")) findElements(By.id("XXX")) findElements(By.name("XXX")) findElements(By.className("XXX")) findElements(By.cssSelector("XXX")) findElements(By.linkText("XXX")) findElements(By.partialLinkText("XXX")) findElements(By.tagName("XXX")) findElements(By.xpath("XXX"))7 执行js脚本//声明一个js执行器 JavascriptExecutor js = (JavascriptExecutor) driver; js.executeScript("alert(123)");
-
Java mybatis中#和$的区别 在mybatis中#和$的主要区别是:#传入的参数在SQL中显示为字符串,$传入的参数在SqL中直接显示为传入的值. #方式能够很大程度防止sql注入,$方式无法防止Sql注入; 1、传入的参数在SQL中显示不同#传入的参数在SQL中显示为字符串(当成一个字符串),会对自动传入的数据加一个双引号。例:使用以下SQLselect id,name,age from student where id =#{id} 当我们传递的参数id为 "1" 时,上述 sql 的解析为: select id,name,age from student where id ="1"$传入的参数在SqL中直接显示为传入的值例:使用以下SQLselect id,name,age from student where id =${id} 当我们传递的参数id为 "1" 时,上述 sql 的解析为: select id,name,age from student where id =12、#可以防止SQL注入的风险(语句的拼接);但$无法防止Sql注入。3、$方式一般用于传入数据库对象,例如传入表名。4、大多数情况下还是经常使用#,一般能用#的就别用$;但有些情况下必须使用$,例:MyBatis排序时使用 order by 动态参数时需要注意,用$而不是#。