搜索到
222
篇与
萧瑟
的结果
-
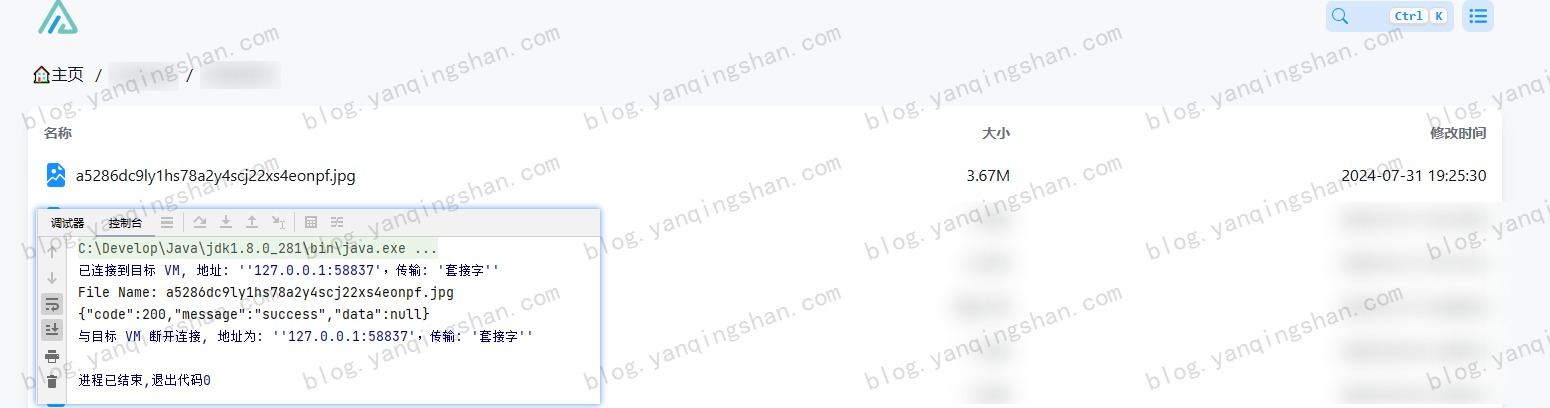
 代码实现:微博图片转存AList 最近想把之前我存在微博的图片转入 AList 中,发现有点问题,原因是微博开启防盗链,无法直接在浏览器中打开或直接拿到文件流,这就造成 AList 无法通过离线下载。原因分析微博图床开启防盗链,所以需要在请求头中携带 Referer ,这样才能获取到流数据。AList 也提供了三方接口,可以自己调用上传文件。详见:AList API文档代码实现上面的常量配置自己的 Alist 信息就可以了,主要是 域名、账号、密码以及上传路径package com.yanqingshan.blog; import cn.hutool.http.ContentType; import cn.hutool.http.Header; import cn.hutool.http.HttpRequest; import cn.hutool.http.HttpResponse; import cn.hutool.json.JSONUtil; import java.util.HashMap; import java.util.Map; /** * 微博上传Alist简单测试 * * @author yanqs * @since 2024-07-31 */ public class WeiBoImgDemo { /** * USER_AGENT */ private static final String USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"; /** * Alist 域名 */ private static final String BASE_URL = ""; /** * Alist 账号 */ private static final String USER_NAME = ""; /** * Alist 密码 */ private static final String PASSWORD = ""; /** * Alist 上传路径 */ private static final String UPLOAD_Path = ""; public static void main(String[] args) { String url = "https://tvax3.sinaimg.cn/large/a5286dc9ly1hs78a2y4scj22xs4eonpf.jpg"; int lastSlashIndex = url.lastIndexOf('/'); // 如果找到了斜杠,就从斜杠后面截取字符串 String fileName = url.substring(lastSlashIndex + 1); System.out.println("File Name: " + fileName); HttpRequest request = HttpRequest.get(url) .header(Header.REFERER, "https://weibo.com/")//头信息,多个头信息多次调用此方法即可 .header(Header.USER_AGENT, USER_AGENT) .timeout(20000); HttpResponse httpResponse = request.executeAsync(); // 获取到文件流 上传到Alist byte[] bytes = httpResponse.bodyBytes(); String result = HttpRequest.put(BASE_URL + "/api/fs/put") .header(Header.AUTHORIZATION, getToken()) .header(Header.CONTENT_TYPE, ContentType.MULTIPART.getValue()) .header("File-Path", UPLOAD_Path + fileName) .body(bytes) .execute().body(); System.out.println(result); } /** * 获取Alist Token * * @return */ public static String getToken() { Map<String, String> params = new HashMap<>(); params.put("username", USER_NAME); params.put("password", PASSWORD); String body = HttpRequest.post(BASE_URL + "/api/auth/login") .header(Header.CONTENT_TYPE, ContentType.JSON.getValue()) .body(JSONUtil.toJsonStr(params)) .execute().body(); return JSONUtil.parseObj(body).getJSONObject("data").getStr("token"); } }注:其中微博图片的链接有多种可选large -> 原始图片oslarge ->无水印 mw690 -> 最大 690 像素宽度裁剪thumbnail -> 缩略图small -> 小图square -> 80 像素正方形裁剪thumb150 -> 150 像素正方形裁剪thumb180 -> 180 像素正方形裁剪thumb300 -> 300 像素正方形裁剪orj180 -> 180 像素宽度原比例缩放orj360 -> 360 像素宽度原比例缩放运行结果运行效果如下后续可以自己建一个txt文件,将微博图片的后缀存起来,然后把上面代码改造一下就可以实现。
代码实现:微博图片转存AList 最近想把之前我存在微博的图片转入 AList 中,发现有点问题,原因是微博开启防盗链,无法直接在浏览器中打开或直接拿到文件流,这就造成 AList 无法通过离线下载。原因分析微博图床开启防盗链,所以需要在请求头中携带 Referer ,这样才能获取到流数据。AList 也提供了三方接口,可以自己调用上传文件。详见:AList API文档代码实现上面的常量配置自己的 Alist 信息就可以了,主要是 域名、账号、密码以及上传路径package com.yanqingshan.blog; import cn.hutool.http.ContentType; import cn.hutool.http.Header; import cn.hutool.http.HttpRequest; import cn.hutool.http.HttpResponse; import cn.hutool.json.JSONUtil; import java.util.HashMap; import java.util.Map; /** * 微博上传Alist简单测试 * * @author yanqs * @since 2024-07-31 */ public class WeiBoImgDemo { /** * USER_AGENT */ private static final String USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"; /** * Alist 域名 */ private static final String BASE_URL = ""; /** * Alist 账号 */ private static final String USER_NAME = ""; /** * Alist 密码 */ private static final String PASSWORD = ""; /** * Alist 上传路径 */ private static final String UPLOAD_Path = ""; public static void main(String[] args) { String url = "https://tvax3.sinaimg.cn/large/a5286dc9ly1hs78a2y4scj22xs4eonpf.jpg"; int lastSlashIndex = url.lastIndexOf('/'); // 如果找到了斜杠,就从斜杠后面截取字符串 String fileName = url.substring(lastSlashIndex + 1); System.out.println("File Name: " + fileName); HttpRequest request = HttpRequest.get(url) .header(Header.REFERER, "https://weibo.com/")//头信息,多个头信息多次调用此方法即可 .header(Header.USER_AGENT, USER_AGENT) .timeout(20000); HttpResponse httpResponse = request.executeAsync(); // 获取到文件流 上传到Alist byte[] bytes = httpResponse.bodyBytes(); String result = HttpRequest.put(BASE_URL + "/api/fs/put") .header(Header.AUTHORIZATION, getToken()) .header(Header.CONTENT_TYPE, ContentType.MULTIPART.getValue()) .header("File-Path", UPLOAD_Path + fileName) .body(bytes) .execute().body(); System.out.println(result); } /** * 获取Alist Token * * @return */ public static String getToken() { Map<String, String> params = new HashMap<>(); params.put("username", USER_NAME); params.put("password", PASSWORD); String body = HttpRequest.post(BASE_URL + "/api/auth/login") .header(Header.CONTENT_TYPE, ContentType.JSON.getValue()) .body(JSONUtil.toJsonStr(params)) .execute().body(); return JSONUtil.parseObj(body).getJSONObject("data").getStr("token"); } }注:其中微博图片的链接有多种可选large -> 原始图片oslarge ->无水印 mw690 -> 最大 690 像素宽度裁剪thumbnail -> 缩略图small -> 小图square -> 80 像素正方形裁剪thumb150 -> 150 像素正方形裁剪thumb180 -> 180 像素正方形裁剪thumb300 -> 300 像素正方形裁剪orj180 -> 180 像素宽度原比例缩放orj360 -> 360 像素宽度原比例缩放运行结果运行效果如下后续可以自己建一个txt文件,将微博图片的后缀存起来,然后把上面代码改造一下就可以实现。 -
CentOS安全加固-IPV6禁止入站请求 之前家宽都申请到了动态公网IP,拥有动态公网IP后,顺手配置 IPV6 公网,且运营商竟然没有封V6的 80 和 443 端口。而且我试了都是可以正常访问,但是网上也有人说,拿来做网站有被封的风险,抱着合规、安全的态度,还是觉得继续使用V4的端口。V6全暴露还是有一定的安全风险,但也还要使用v6访问其他外网服务,所以研究一下如何关闭入站请求。配置防火墙策略禁止 udp 和 tcp 流量入站firewall-cmd --permanent --zone=public --add-rich-rule='rule family="ipv6" protocol value="tcp" source address="::/0" reject' firewall-cmd --permanent --zone=public --add-rich-rule='rule family="ipv6" protocol value="udp" source address="::/0" reject' firewall-cmd --reload这样就封了入站请求,加固了一下ipv6的安全。
-
-
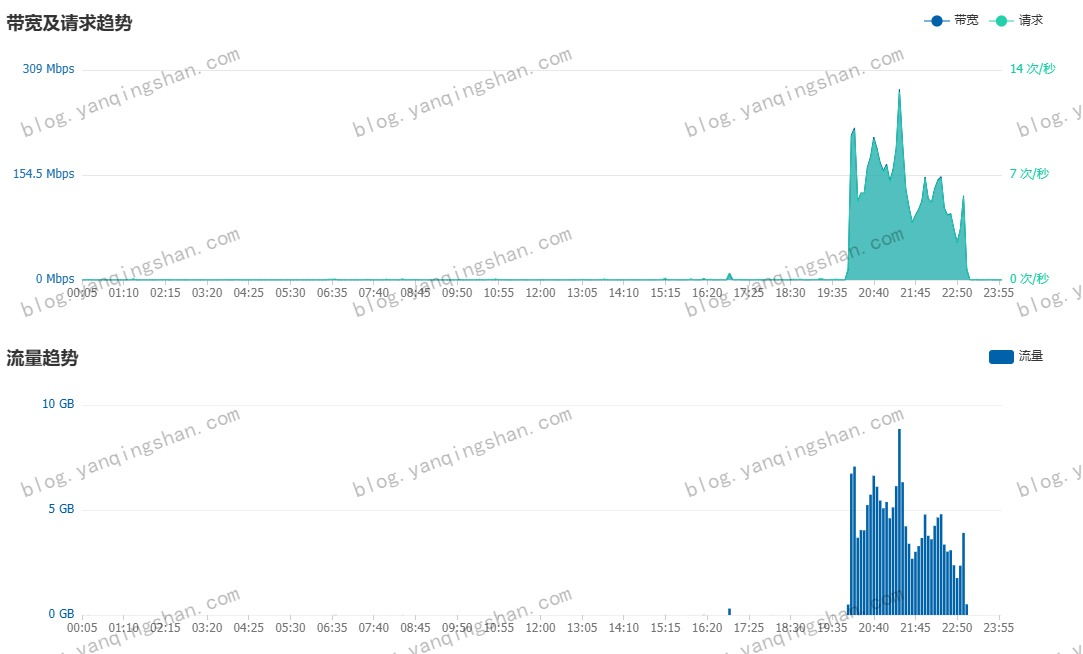
《抓娃娃》点映随笔 最近工作比较忙,博客也好久没打理过了,自从7月5日网站图片站被恶意刷流量后,基本每晚都在处理CDN的事情,12日将山西联通解析修改为127.0.0.1 也未解决这件事,索性就把 CDN 服务关闭,域名停止解析。今日感觉稍微好些了。请求\流量没看到有动静。昨晚忙中偷闲,去看了开心麻花出品的,还未正式上映的点映《抓娃娃》。大概写一下,观影的随笔(之前每次叫观后感,感觉还是随笔比较好些)。电影一开始,上接西虹市系列的背景,首先看到的是西红人寿,再紧接来到本片主角的居住地。就不剧透了...这片我感觉像是育儿版《楚门的世界》,富养大俊,结果不俊;穷养继业,结果不继,富养溺爱与穷养鞭策都太过极端。父母总是给你做任何决定,然后说为你好,这就是中国父母爱孩子的方式。继业发现秘密后,父母赶到跟前后,继业一句 “你们是哪位老师呀?墙上没有介绍你俩…”这句台词如果让哪位家长听了,心不是被扎得千疮百孔的!小结就用本片主题曲《我想当风》作为结尾。{music-list id="12308839004" color="#1989fa" autoplay="autoplay"/}
-
-
-
-
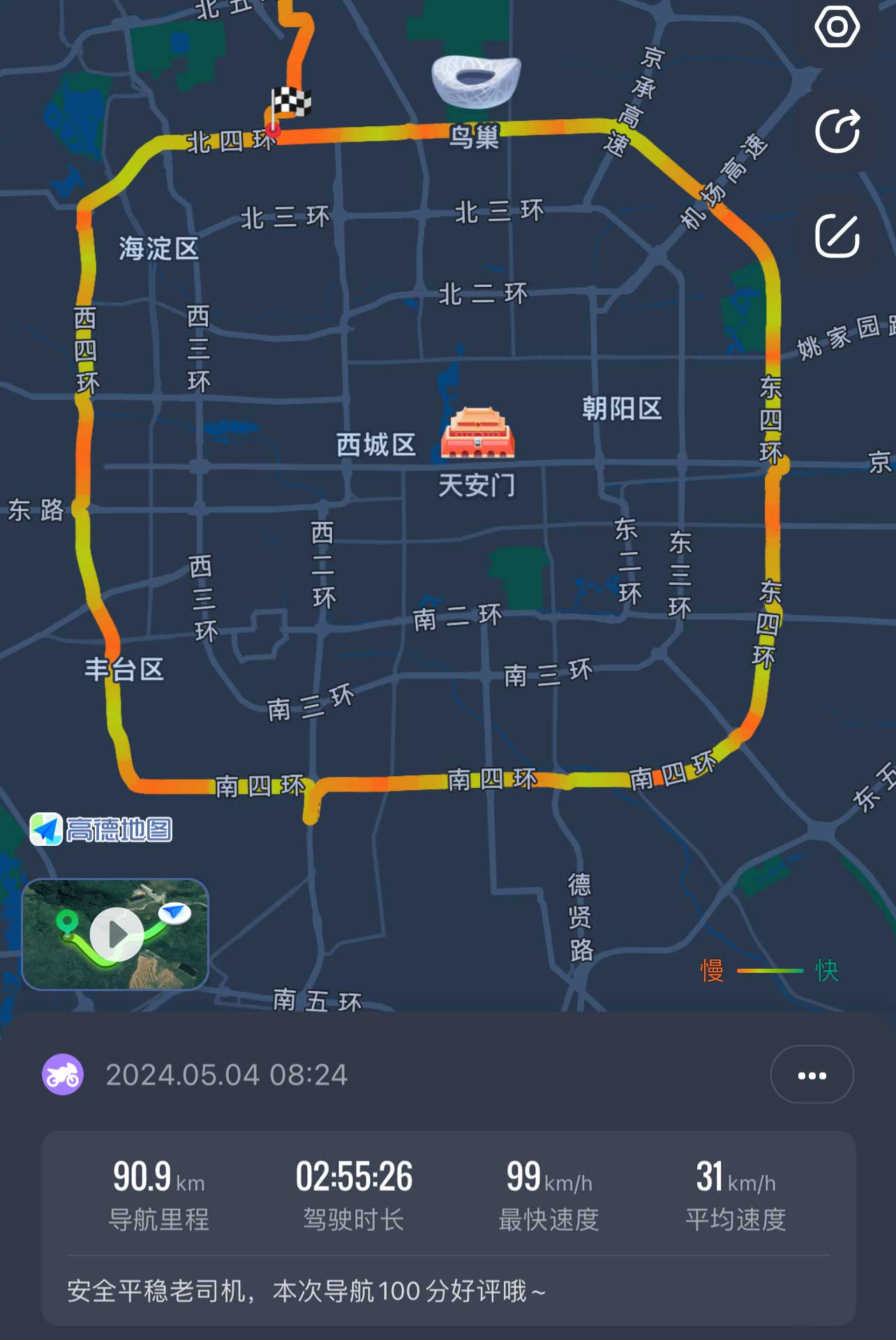
道路千万条,安全第一条 青年节闲来无事,便骑车跑四环,耗时2小时;再次路过南四环的时候,早已物是人非。道路安全因为最近后轮胎压经常不稳,老是没气,准备买个胎压监测,方便我及时为轮胎补气。上午刚跑完四环,下午快递就到了,迫不及待的换上后,感觉还不错。马上骑上去接小可爱下班,刚上高速没多久,就开始堵车,走着走着感觉不对劲,感觉像是轮胎没气了,就赶紧下高速,停在路边,发现这胎压监测的气嘴已经爆掉了。还好高速堵车,不然跑快一点,我可能就没了。停在路边,打起双闪,一个路过的闪送大哥热情的跑过来,问我怎么了,我把事情告诉他,他热心的帮我打好了气,我估计应该能撑回去,掉头回家,刚走过一个桥,再次感觉到轮胎开始滑动,左右起伏。立马停在路边,等待小可爱回家带装备前来救援。从家带来装备,打好气后,赶紧找个修车地方,换个了轮胎。这次教训真的很长记性,简直是捡了芝麻丢西瓜,为了一个5块钱的便宜胎压监测而花了三百多换了一个胎。不过最好的结果就是没出事故,小命还在...
-
-
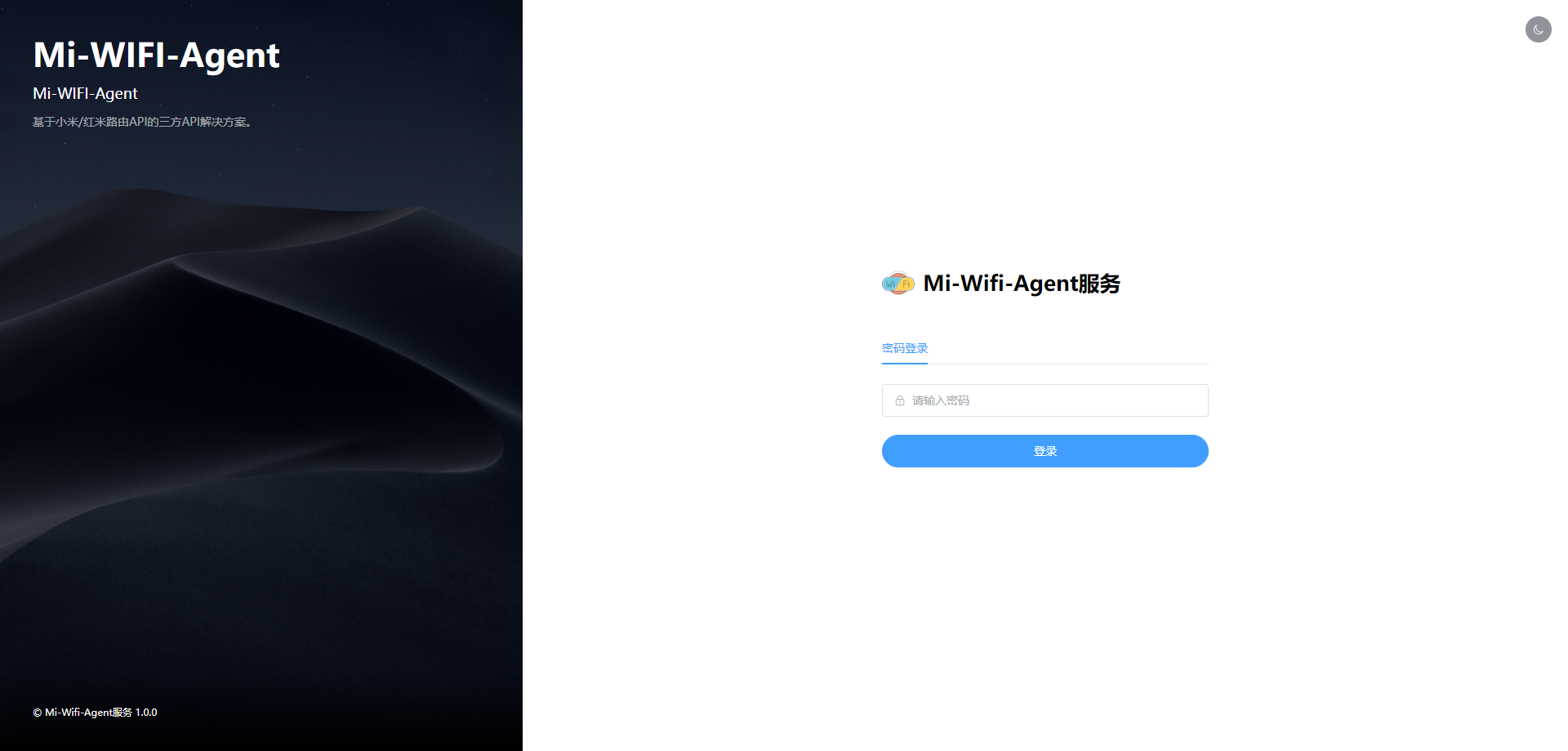
小米/红米路由器Agent 服务正式上线 最近发现家里的路由器,每次配置还需要组网,然后登录管理页面,想着弄一个Agent服务,通过Agent 服务来管理路由器的端口映射,后期还可以对接到我的统管平台中去。在内网的服务器中,部署一个docker镜像,通过容器中的Agent服务对路由器的API接口进行转发,目前1.0.0版本,只做了一个简单的路由器状态查看和端口映射管理。部署docker pull bcrjl/miwifi-agent:latestdocker run -d --name miwifi-agent \ --restart always \ -p 24317:24317 \ -e BMW_URL=192.168.31.1 \ -e BMW_PASSWORD=123456 \ -e WEB_PASSWORD=123456 \ miwifi-agent:latest阿里云镜像docker pull registry.cn-hangzhou.aliyuncs.com/bcrjl/miwifi-agent:latestdocker run -d --name miwifi-agent \ --restart always \ -p 24317:24317 \ -e BMW_URL=192.168.31.1 \ -e BMW_PASSWORD=123456 \ -e WEB_PASSWORD=123456 \ miwifi-agent:latest其中BMW_URL指路由器IP地址,BMW_PASSWORD指路由器密码,WEB_PASSWORD 平台设置的密码。运行成功后访问 http://[IP]:24317运行效果项目地址https://github.com/bcrjl/miwifi-agent如果有想一起维护的小伙伴,可以联系我。