搜索到
2
篇与
华为
的结果
-
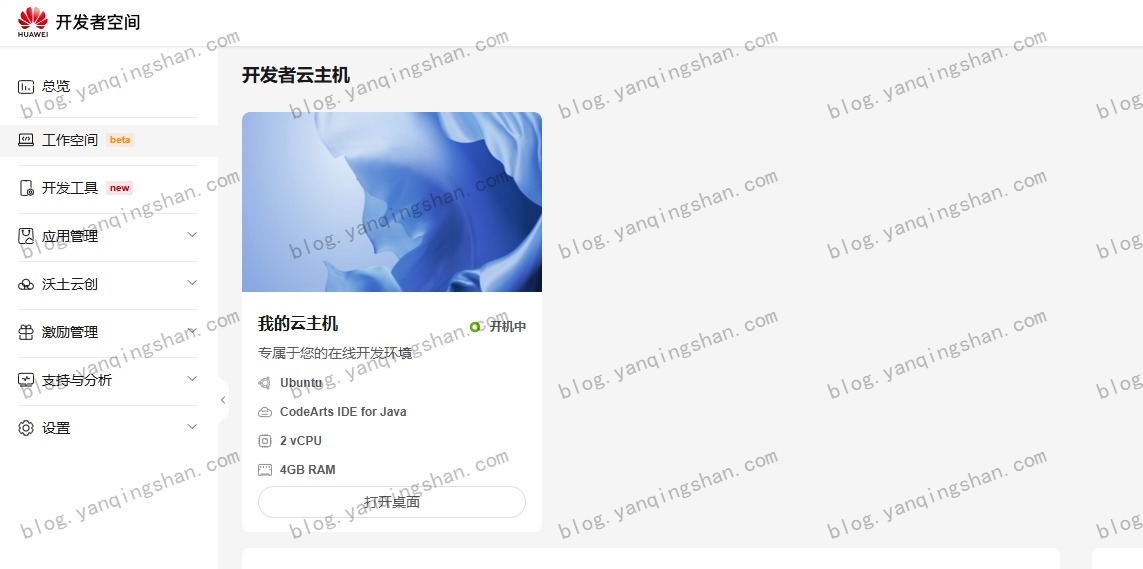
 (限量)体验华为云开发者空间云桌面 今天偶然看到信息流推送"华为云可领取开发者空间云桌面",就点开看了看并开始试用。使用说明进入主机桌面前云主机在领取后,首次进入前会初始化云端资源,大约需要3分钟。点击进入桌面,加载云端系统桌面,需要大约1分钟的等待时间。请将您自己电脑的输入法切换成英文,以便在云主机内能够正常输入进入主机桌面后进入主机后,初始默认可使用时长为15小时,剩余时长小于10分钟后,可以点击延时按钮继续使用。为了保证数据的隐私安全,本地主机和云主机之间的数据传输通过安全剪贴板来传输。云主机内提供了关机操作,为避免时长额度浪费,在您不用的时候请关机。如果您长时间未使用云主机,我们将对资源进行回收,以服务更多的开发者。当前功能为“限量体验”阶段。系统配置Ubuntu系统,2C4G,5GB存储空间,有效期15小时,不足10分钟时可续期。不需要使用时可关机节省时间,长期闲置资源将会被回收。单独跑Java项目还是有些卡,建议优化一下 CodeArts IDE. 跑跑前端还是可以的。体验(领取)地址https://developer.huaweicloud.com/space/devportal/desktop
(限量)体验华为云开发者空间云桌面 今天偶然看到信息流推送"华为云可领取开发者空间云桌面",就点开看了看并开始试用。使用说明进入主机桌面前云主机在领取后,首次进入前会初始化云端资源,大约需要3分钟。点击进入桌面,加载云端系统桌面,需要大约1分钟的等待时间。请将您自己电脑的输入法切换成英文,以便在云主机内能够正常输入进入主机桌面后进入主机后,初始默认可使用时长为15小时,剩余时长小于10分钟后,可以点击延时按钮继续使用。为了保证数据的隐私安全,本地主机和云主机之间的数据传输通过安全剪贴板来传输。云主机内提供了关机操作,为避免时长额度浪费,在您不用的时候请关机。如果您长时间未使用云主机,我们将对资源进行回收,以服务更多的开发者。当前功能为“限量体验”阶段。系统配置Ubuntu系统,2C4G,5GB存储空间,有效期15小时,不足10分钟时可续期。不需要使用时可关机节省时间,长期闲置资源将会被回收。单独跑Java项目还是有些卡,建议优化一下 CodeArts IDE. 跑跑前端还是可以的。体验(领取)地址https://developer.huaweicloud.com/space/devportal/desktop -
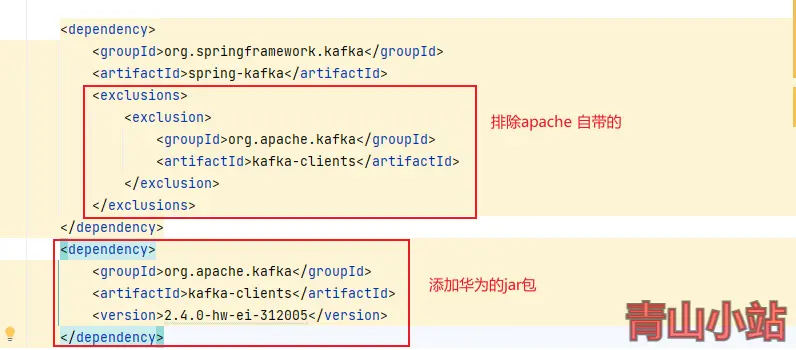
SpringBoot 对接华为大数据平台kerberos认证的Kafka数据 最近项目中有用到kafka来同步某业务核心数据,通过kafka来进行数据的实时更新。原本使用的是Apache kafka 来进行订阅消费,后因业务方信创要求,更换了华为大数据平台的Kafka数据源,采用kerberos认证。对接了一天多,数据才接入成功,网上相关文档比较少,这里我总结一下,为后人少踩坑。本次使用的是华为MRS3.1.2版本,其他版本应该都类似。修改项目中的pom.xml依赖,将默认的apache的kafka-client包替换为华为自带的。如果拉去不到相关依赖包,请更换为华为Maven镜像,配置信息如下。<repositories> <repository> <id>huawei-cloud-sdk</id> <name>HuaWei Cloud Mirrors</name> <url>https://mirrors.huaweicloud.com/repository/maven/huaweicloudsdk/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>true</enabled> </snapshots> </repository> <repository> <id>huawei-mirrors</id> <name>HuaWei Mirrors</name> <url>https://repo.huaweicloud.com/repository/maven/</url> </repository> </repositories>我们需要在配置文件中增加新的配置文件,不要使用spring.kafka相关配置,建议自己新增一个配置信息,本文以huawei.mrs.kafka为例。huawei: mrs: kafka: enable: false bootstrap-servers: 10.244.231.2:21007,10.244.230.202:21007,10.244.230.125:21007 security: protocol: SASL_PLAINTEXT kerberos: domain: name: hadoop.hadoop_651_arm.com sasl: kerberos: service: name: kafka新建一个配置文件HuaWeiMrsKafkaConfiguration,配置相关信息@Value("${huawei.mrs.kafka.enable}") public Boolean enable; @Value("${huawei.mrs.kafka.bootstrap-servers}") public String boostrapServers; @Value("${huawei.mrs.kafka.security.protocol}") public String securityProtocol; @Value("${huawei.mrs.kafka.kerberos.domain.name}") public String kerberosDomainName; @Value("${huawei.mrs.kafka.sasl.kerberos.service.name}") public String kerberosServiceName; @Bean public ConcurrentKafkaListenerContainerFactory<?, ?> kafkaListenerContainerFactory( ConcurrentKafkaListenerContainerFactoryConfigurer configurer, ConsumerFactory<Object, Object> kafkaConsumerFactory, KafkaTemplate<String, String> template) { ConcurrentKafkaListenerContainerFactory<Object, Object> factory = new ConcurrentKafkaListenerContainerFactory<>(); configurer.configure(factory, kafkaConsumerFactory); //禁止消费者自启动,达到动态启动消费者的目的 factory.setAutoStartup(enable); return factory; } @Bean public ConsumerFactory<Object, Object> consumerFactory() { Map<String, Object> configs = new HashMap<>(); configs.put("security.protocol", securityProtocol); configs.put("kerberos.domain.name", kerberosDomainName); configs.put("bootstrap.servers", boostrapServers); configs.put("sasl.kerberos.service.name", kerberosServiceName); configs.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); configs.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); return new DefaultKafkaConsumerFactory<>(configs); } @Bean public KafkaTemplate<String, String> kafkaTemplate() { Map<String, Object> configs = new HashMap<>(); configs.put("security.protocol", securityProtocol); configs.put("kerberos.domain.name", kerberosDomainName); configs.put("bootstrap.servers", boostrapServers); configs.put("sasl.kerberos.service.name", kerberosServiceName); configs.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); configs.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); ProducerFactory<String, String> producerFactory = new DefaultKafkaProducerFactory<>(configs); return new KafkaTemplate<>(producerFactory); } @Bean public RecordMessageConverter converter() { return new StringJsonMessageConverter(); }再新建一个全局消费kafka数据的KafkaConsumer类@Slf4j @Component public class KafkaConsumer { @KafkaListener(topics = "topic1") public void topicMessage(ConsumerRecord<?, ?> record) { log.info("Kafka->topic:‘topic1’-->{}", record.value()); //TODO:业务逻辑 } }配置kerberos信息,也是非常重要的一步,配置kerberos认证文件,本文将以最简单的教程为例,在启动脚本中配置。为什么不在项目中配置呢?因为各位的项目都各自不同,放在resources目录中,有的时候会读取不到,所以我们以最简单的例子来作为讲解。打包项目,将打包好的jar放置在服务器中。并将下载安全集群认证用户的krb5.conf和user.keytab文件放置跟jar包相同目录或者自定义一个目录(本文以/data/java/huawei-mrs-kafka为例)。在这个文件夹或者部署目录通缉新建一个jaas.conf文件,将keyTab项修改为绝对路径。principal则是华为大数据平台提供的账号。Client { com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true keyTab="/data/java/huawei-mrs-kafka/user.keytab" principal="developuser@HADOOP_651_ARM.COM" useTicketCache=false storeKey=true debug=true; }; KafkaClient { com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true keyTab="/data/java/huawei-mrs-kafka/user.keytab" principal="developuser@HADOOP_651_ARM.COM" useTicketCache=false storeKey=true debug=true; }; 最后一步,运行jar包,指定krb5.conf和jaas.conf环境变量。java -jar -Djava.security.krb5.conf=/data/java/huawei-mrs-kafka/krb5.conf -Djava.security.auth.login.config=/data/java/huawei-mrs-kafka/jaas.conf huawei-mrs-kafka-1.0-SNAPSHOT.jar因为本地没有相关环境,生产环境又处于内网,这里就不提供相关运行成功的代码,对接华为大数据平台的Kafka其实很简单,只是网上的教程很少而已。如有这方面的问题,可以在本文留言,看到了就会回复。{cloud title="示例下载" type="default" url="https://www.gitlink.org.cn/yanqs/huawei-mrs-kafka-demo" password=""/}