搜索到
49
篇与
码海
的结果
-

-
-
-
-
-
-
-
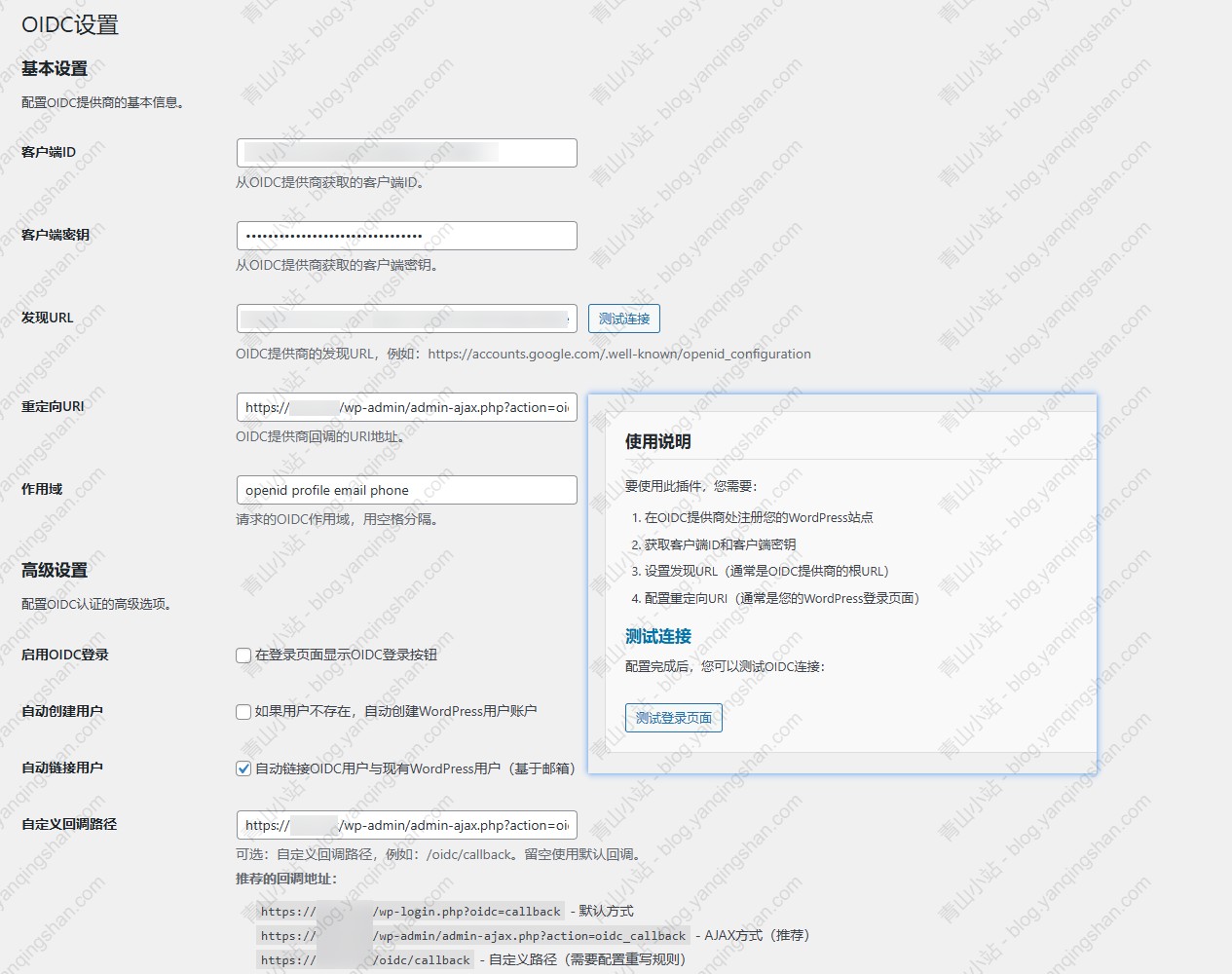
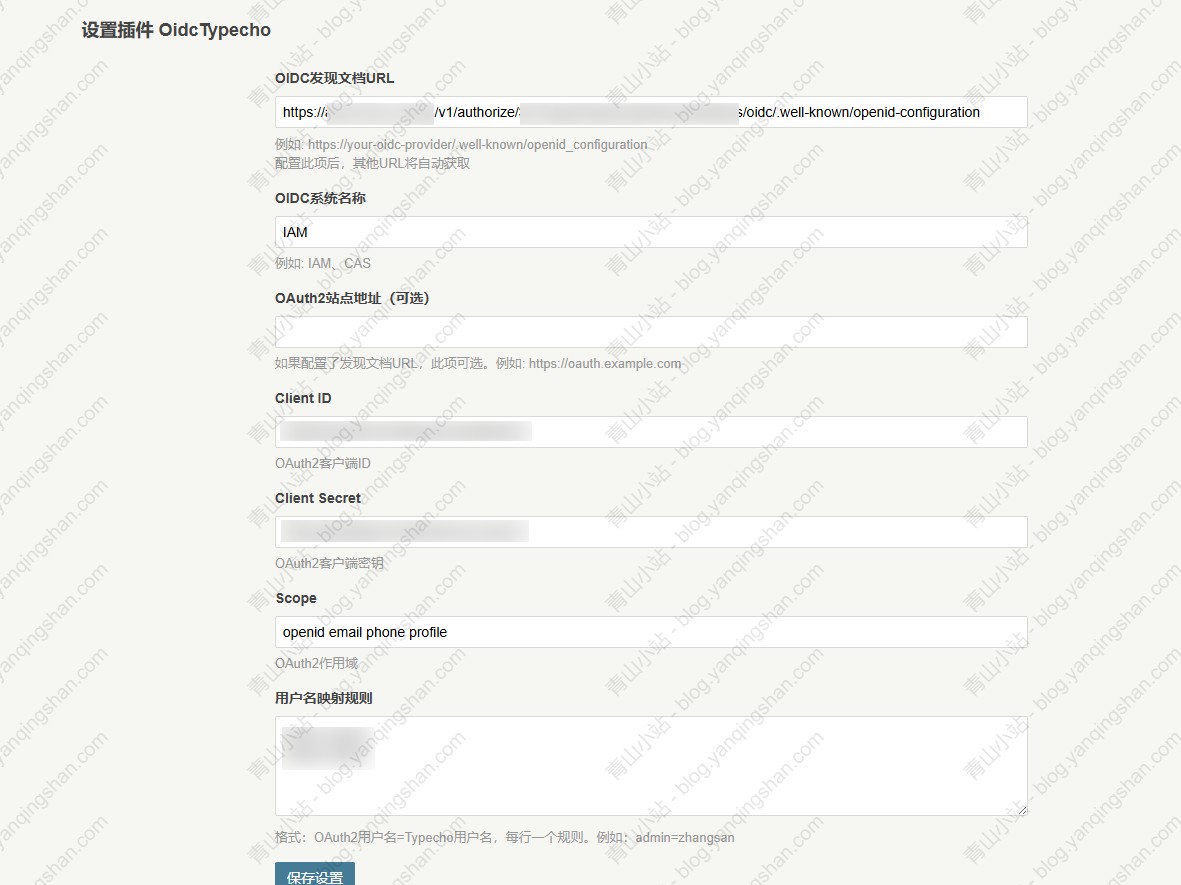
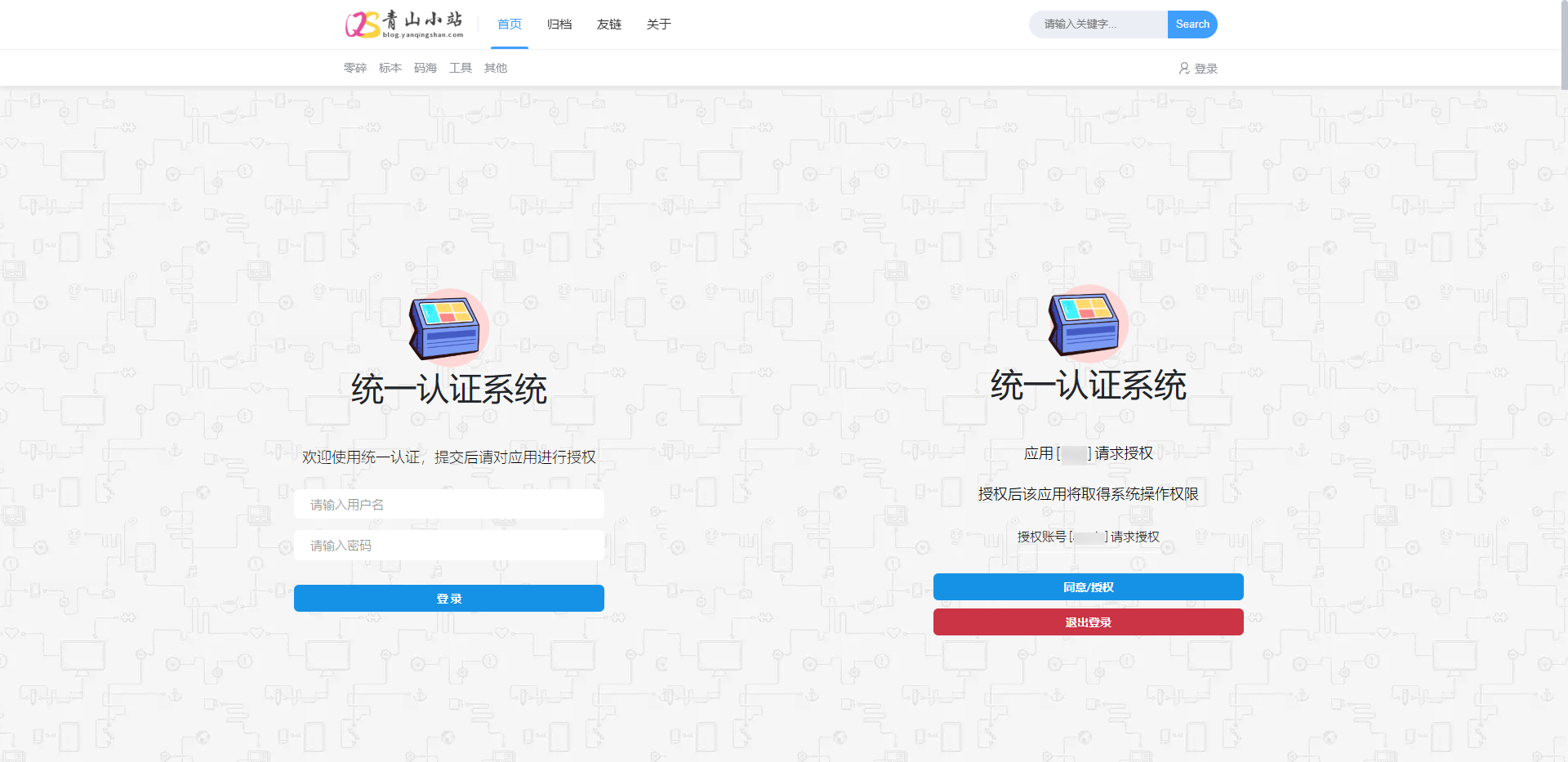
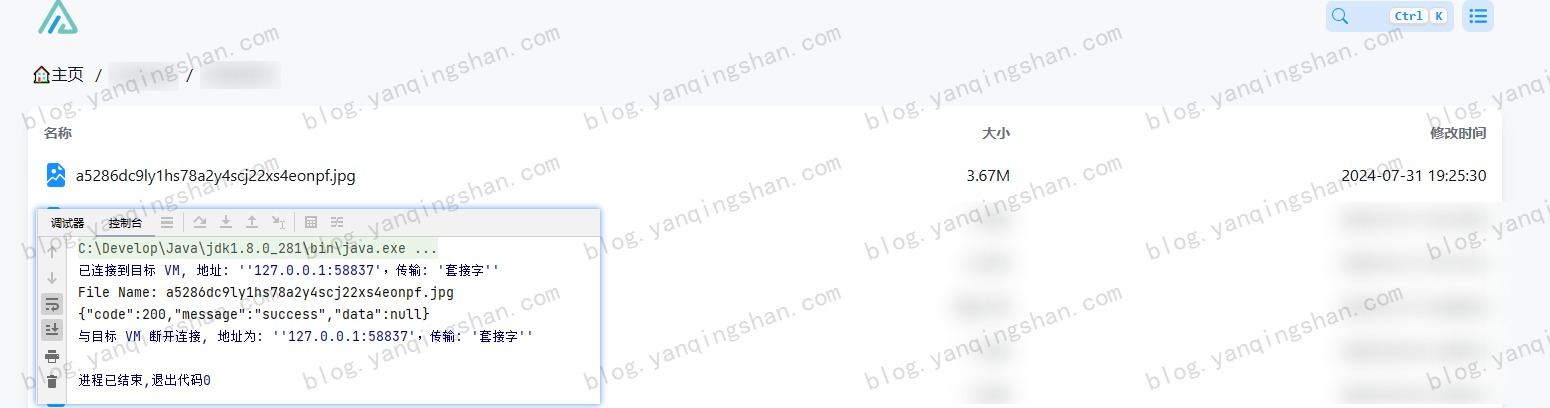
代码实现:微博图片转存AList 最近想把之前我存在微博的图片转入 AList 中,发现有点问题,原因是微博开启防盗链,无法直接在浏览器中打开或直接拿到文件流,这就造成 AList 无法通过离线下载。原因分析微博图床开启防盗链,所以需要在请求头中携带 Referer ,这样才能获取到流数据。AList 也提供了三方接口,可以自己调用上传文件。详见:AList API文档代码实现上面的常量配置自己的 Alist 信息就可以了,主要是 域名、账号、密码以及上传路径package com.yanqingshan.blog; import cn.hutool.http.ContentType; import cn.hutool.http.Header; import cn.hutool.http.HttpRequest; import cn.hutool.http.HttpResponse; import cn.hutool.json.JSONUtil; import java.util.HashMap; import java.util.Map; /** * 微博上传Alist简单测试 * * @author yanqs * @since 2024-07-31 */ public class WeiBoImgDemo { /** * USER_AGENT */ private static final String USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"; /** * Alist 域名 */ private static final String BASE_URL = ""; /** * Alist 账号 */ private static final String USER_NAME = ""; /** * Alist 密码 */ private static final String PASSWORD = ""; /** * Alist 上传路径 */ private static final String UPLOAD_Path = ""; public static void main(String[] args) { String url = "https://tvax3.sinaimg.cn/large/a5286dc9ly1hs78a2y4scj22xs4eonpf.jpg"; int lastSlashIndex = url.lastIndexOf('/'); // 如果找到了斜杠,就从斜杠后面截取字符串 String fileName = url.substring(lastSlashIndex + 1); System.out.println("File Name: " + fileName); HttpRequest request = HttpRequest.get(url) .header(Header.REFERER, "https://weibo.com/")//头信息,多个头信息多次调用此方法即可 .header(Header.USER_AGENT, USER_AGENT) .timeout(20000); HttpResponse httpResponse = request.executeAsync(); // 获取到文件流 上传到Alist byte[] bytes = httpResponse.bodyBytes(); String result = HttpRequest.put(BASE_URL + "/api/fs/put") .header(Header.AUTHORIZATION, getToken()) .header(Header.CONTENT_TYPE, ContentType.MULTIPART.getValue()) .header("File-Path", UPLOAD_Path + fileName) .body(bytes) .execute().body(); System.out.println(result); } /** * 获取Alist Token * * @return */ public static String getToken() { Map<String, String> params = new HashMap<>(); params.put("username", USER_NAME); params.put("password", PASSWORD); String body = HttpRequest.post(BASE_URL + "/api/auth/login") .header(Header.CONTENT_TYPE, ContentType.JSON.getValue()) .body(JSONUtil.toJsonStr(params)) .execute().body(); return JSONUtil.parseObj(body).getJSONObject("data").getStr("token"); } }注:其中微博图片的链接有多种可选large -> 原始图片oslarge ->无水印 mw690 -> 最大 690 像素宽度裁剪thumbnail -> 缩略图small -> 小图square -> 80 像素正方形裁剪thumb150 -> 150 像素正方形裁剪thumb180 -> 180 像素正方形裁剪thumb300 -> 300 像素正方形裁剪orj180 -> 180 像素宽度原比例缩放orj360 -> 360 像素宽度原比例缩放运行结果运行效果如下后续可以自己建一个txt文件,将微博图片的后缀存起来,然后把上面代码改造一下就可以实现。
-
-
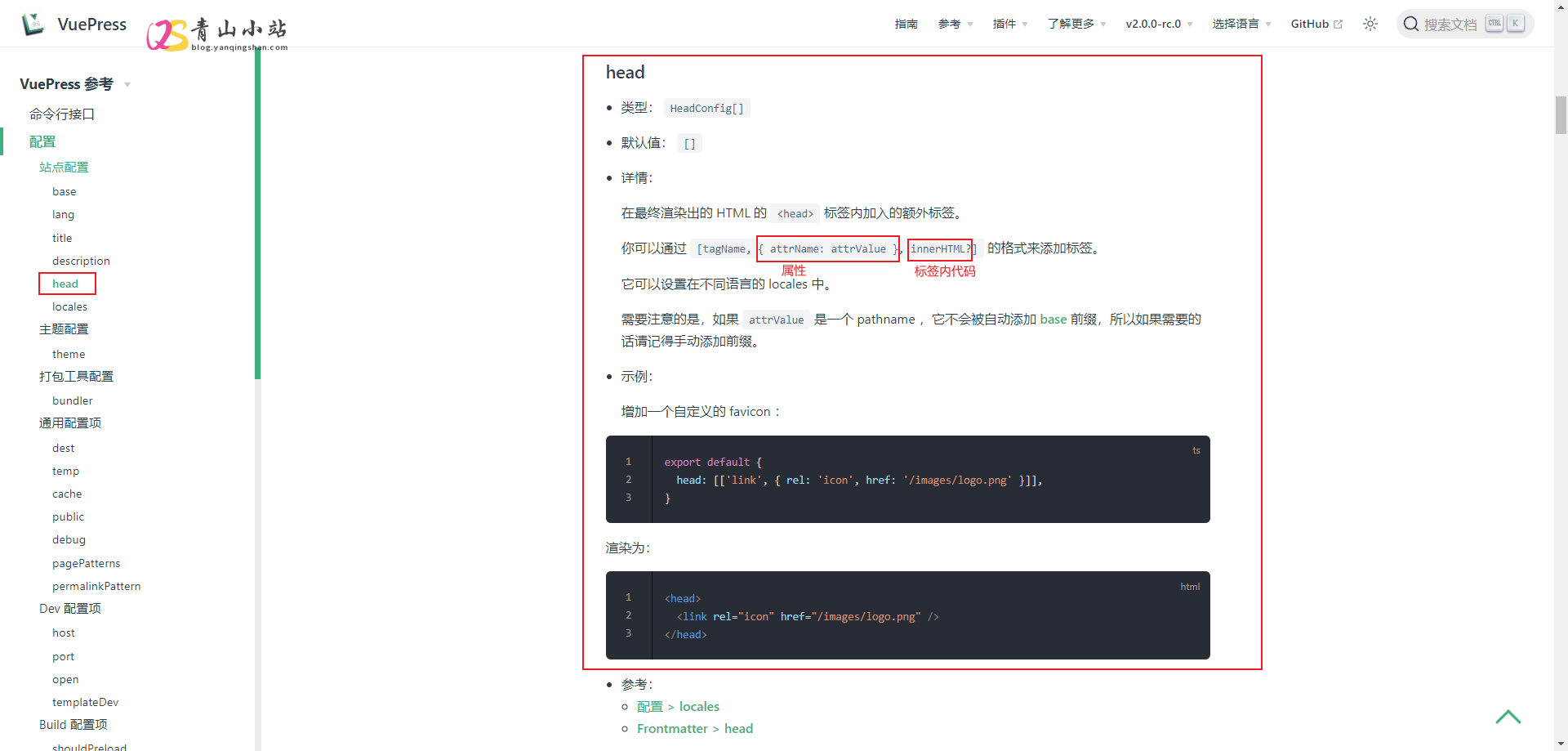
VuePress 配置51LA/统计鸟统计代码 自从 语雀 付费和异常后,我也急需一款 Wiki知识手册 ,考虑了Hexo、GitBook、Docsify 等,感觉都各自有优缺点,最后选择了VuePress 2.0.0 搭建属于自己的私有化 Wiki知识手册 。使用过程中都还比较顺利,但是突然间发现跟其他 Vue 项目有点不太一样,少了一个 index.html ,这样不能在全局文件中引用/配置统计代码,刚好晚上在写知识手册的时候,看了一眼官方的说明文档,然后分享了一下统计代码,终于配置出来了。在全局 config.js 配置文件 head 参数中添加,就最终渲染出的 HTML 的 <head> 标签内加入的额外标签。但是之前一直添加不成功,后来分析了一下参数,这里以51LA为例。图上标注的红色就相当于红和绿就相当于第二个参数 { attrName: attrValue } ,而黄色就相当于最后一个参数 innerHTML? 那这样分析后,我们就可以这样写。head: [ ['script',{type:'text/javascript',src:'https://api.tongjiniao.com/c?_=***',async:''}], ['script',{charset:'UTF-8',id:'LA_COLLECT',src:'https://sdk.51.la/js-sdk-pro.min.js'}], ['script',{},'LA.init({id:"*****",ck:"*****",autoTrack:true,hashMode:true})'], ['script',{src: 'https://sdk.51.la/perf/js-sdk-perf.min.js',crossorigin:'anonymous'}], ['script',{},'new LingQue.Monitor().init({id:"******",sendSuspicious:true,sendSpaPv:true});'] ]第一个数组是统计鸟的,第二三数组是51LA的,第三四数组是51LA灵雀应用监控平台的。(注:其中官方的参数均使用**代替)至此,统计代码就安装完成了,如果要在 head 中引用其他脚本,也可以参考这样的写法。